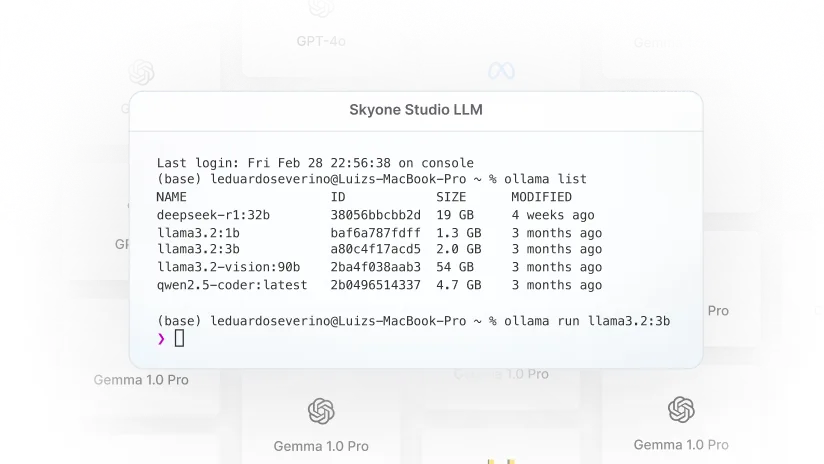
Serveur d'inférence
Exécutez vos modèles d'IA en production avec des performances et une évolutivité optimales. Le serveur d'inférence de Skyone offre un environnement dédié et optimisé, garantissant agilité et efficacité pour votre usine d'IA.
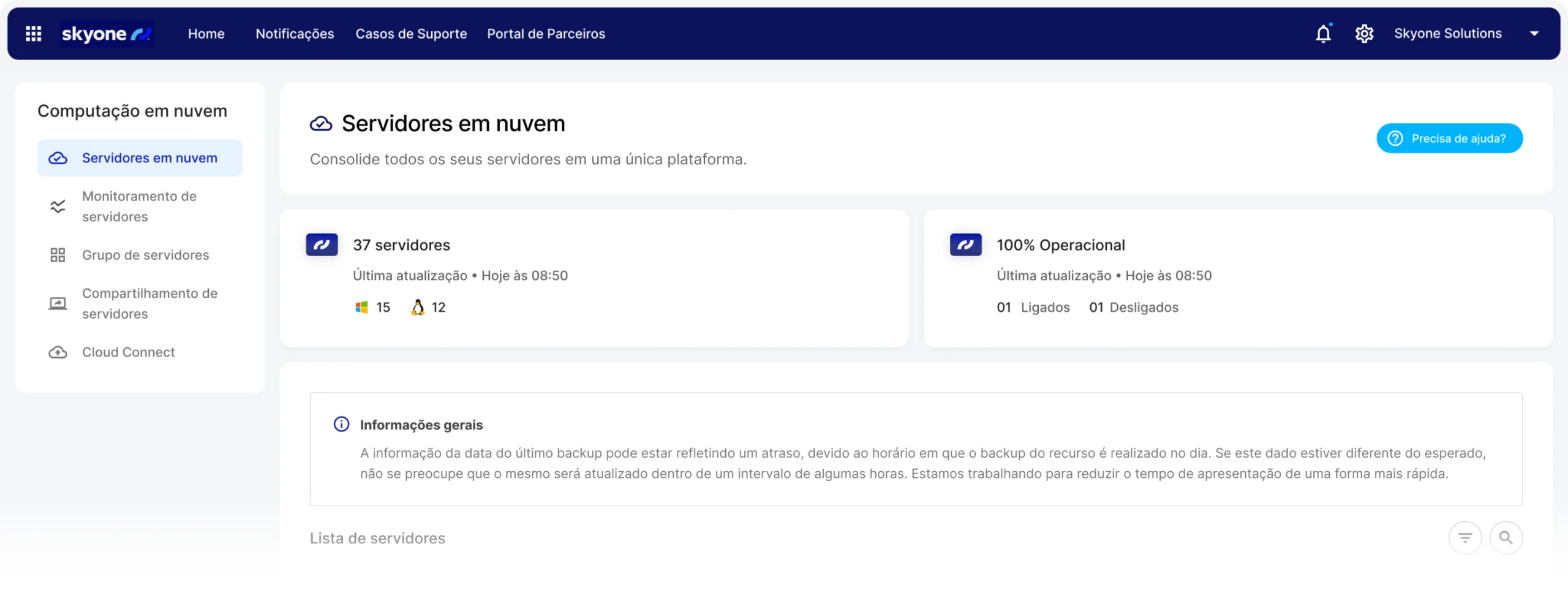
Ce dont votre entreprise a besoin pour se développer
Performances optimisées avec GPU et LLM
Utilisez une infrastructure GPU dédiée et optimisée pour le traitement des modèles de langage (LLM), comme LLAMA 3 et Gemini 1.5 Pro. Cela garantit l'exécution des tâches d'IA et des agents autonomes avec des performances élevées et une latence minimale, essentielles pour les applications en temps réel.
Évolutivité à la demande
Votre usine d'IA évolue sans goulots d'étranglement. Le serveur d'inférence s'intègre à l'infrastructure de Skyone pour garantir une évolutivité adaptée à l'évolution de la demande. Vous pouvez ainsi augmenter ou diminuer les ressources de traitement, optimiser les coûts et maintenir la productivité sans gaspillage.
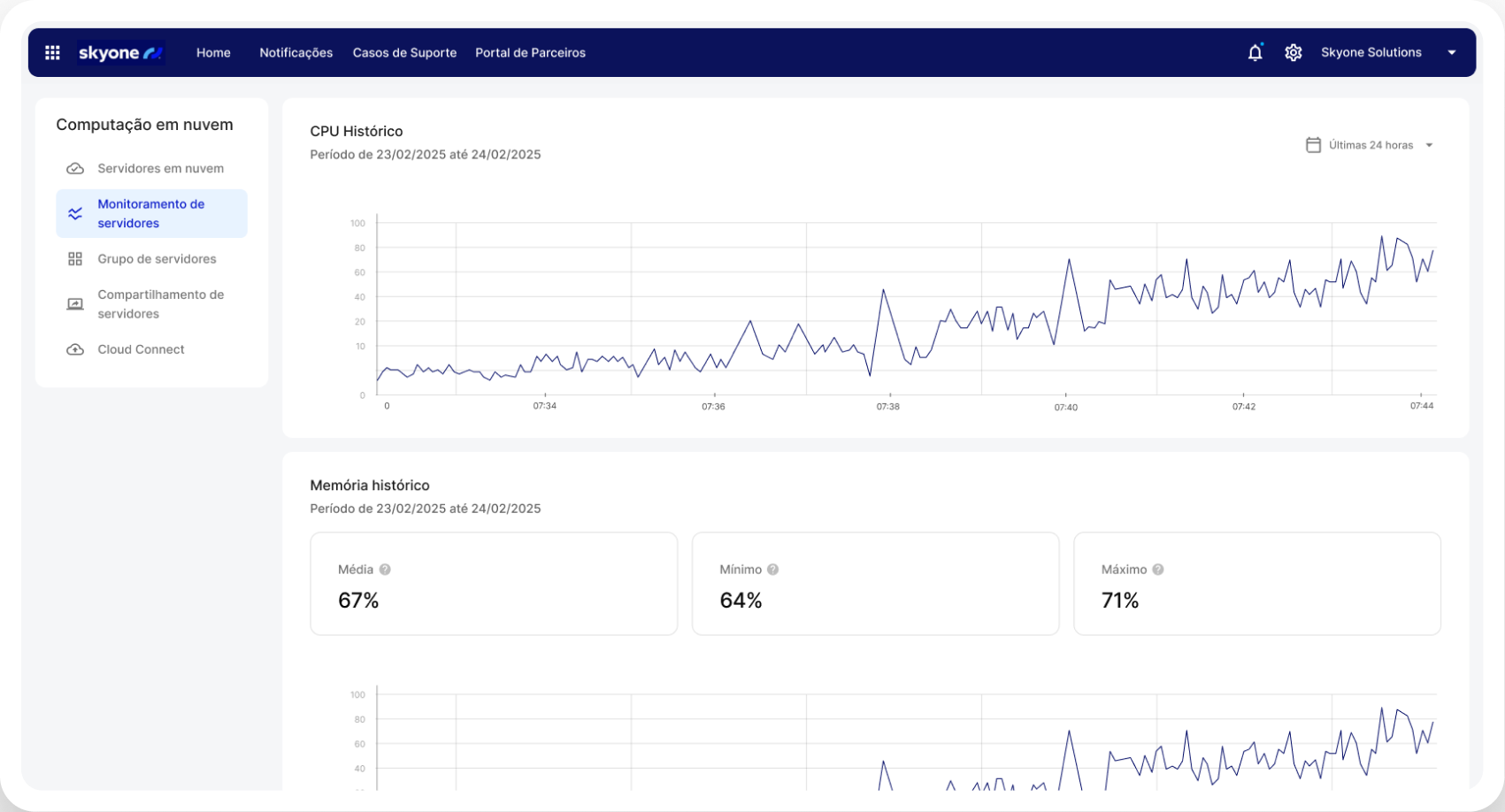
Maîtrise totale des coûts par l'usage
Gagnez en prévisibilité et en efficacité financière. Grâce à des serveurs optimisés, vous ne payez que pour la puissance de traitement (GPU) et les ressources utilisées. Un atout essentiel pour l'IA et les opérations financières, car il permet une innovation viable et un retour sur investissement (ROI) clair.
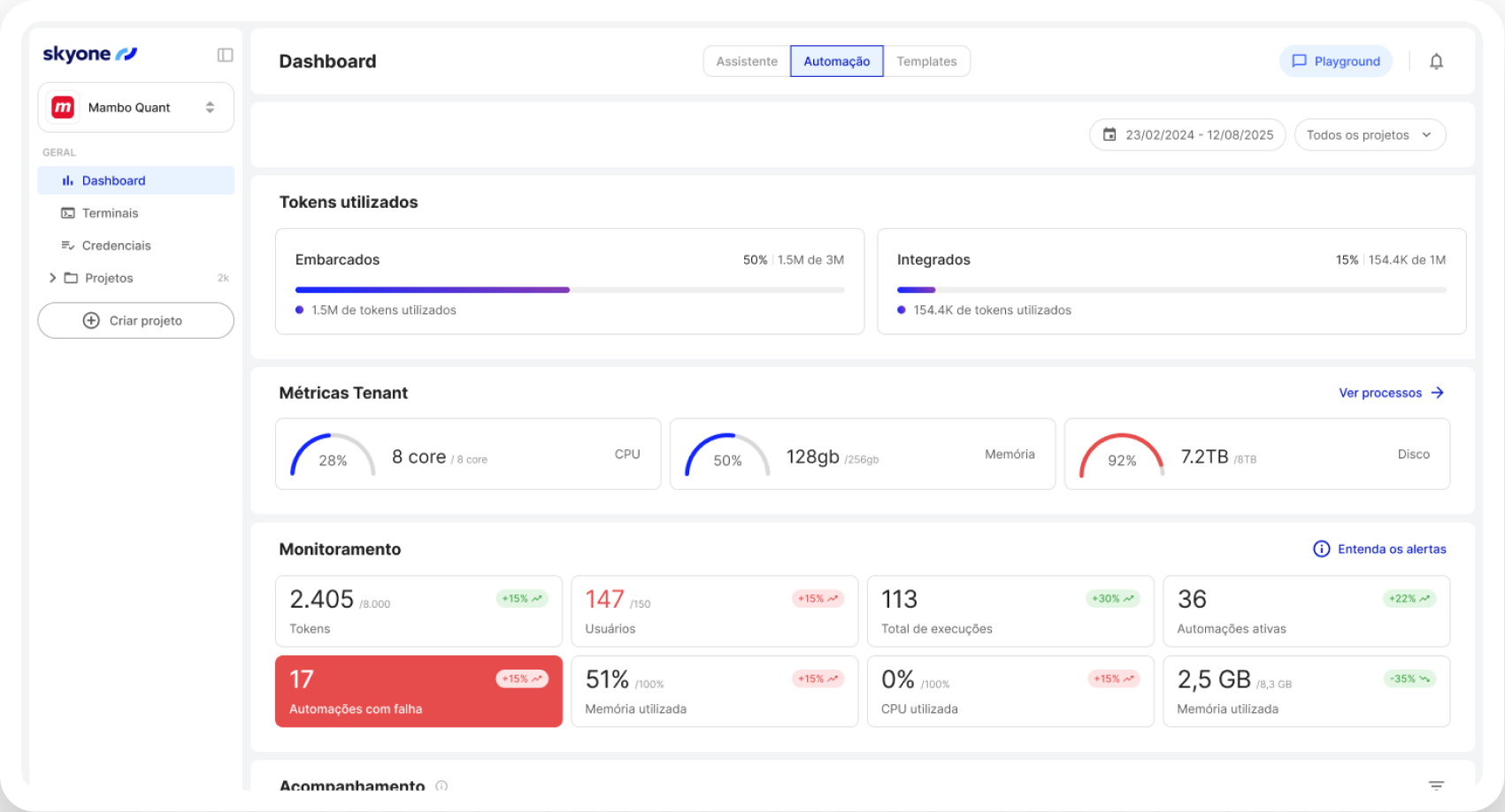
Comment ça marche
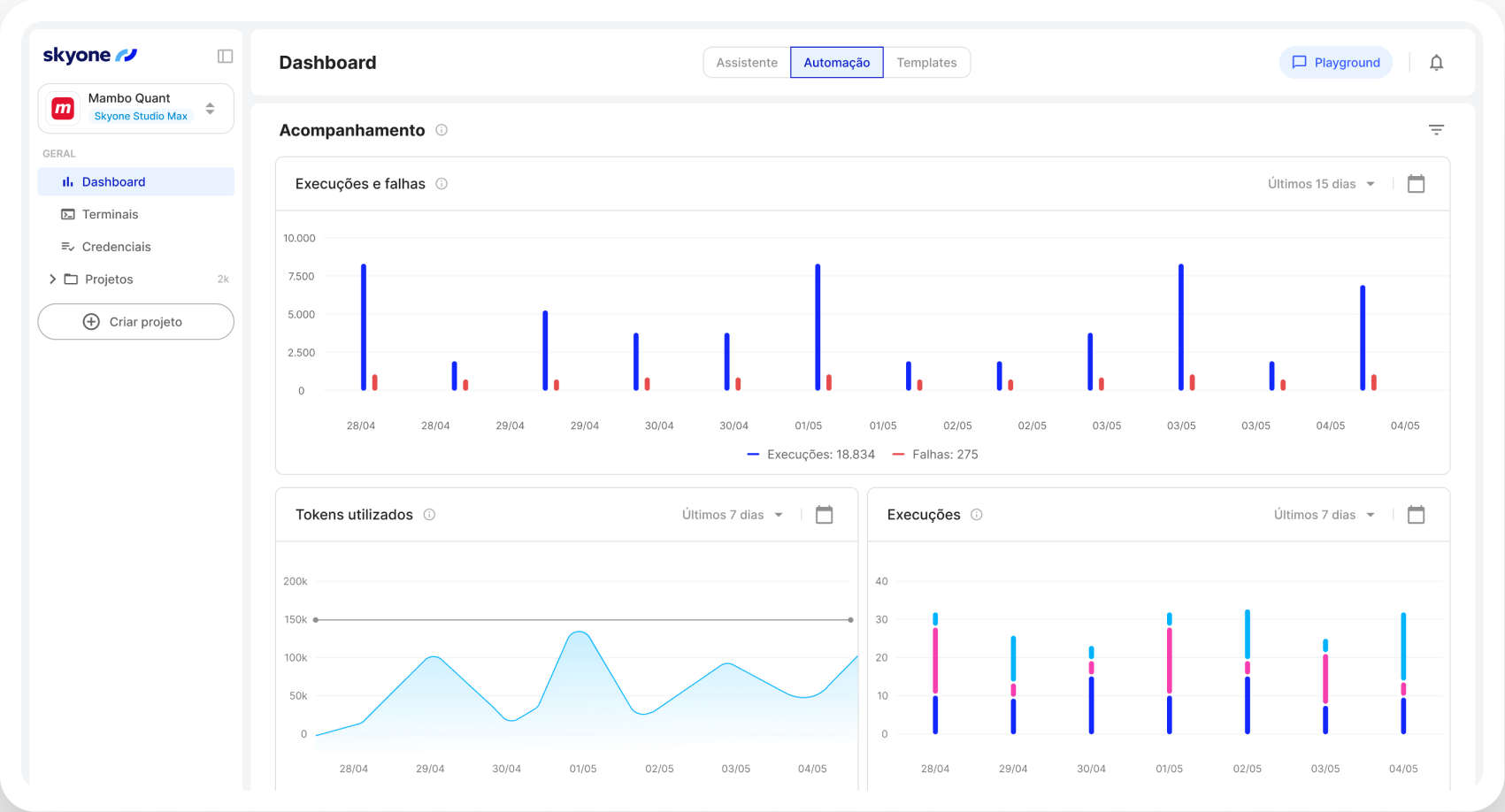
Le serveur d'inférence exécute les modèles d'IA dans Skyone Studio avec des performances élevées, garantissant des réponses rapides et efficaces pour les applications métier après l'entraînement ou la sélection du modèle.
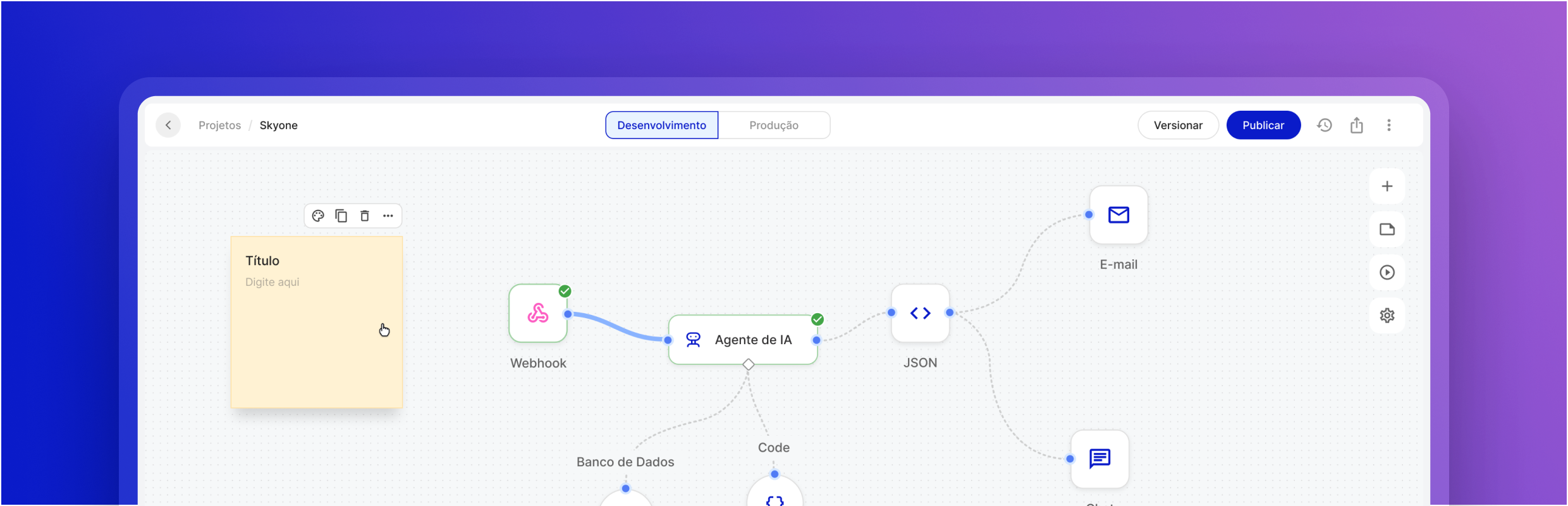
Optimisez votre activité grâce au serveur d'inférence
Prise en charge de plusieurs modèles (LLM/LMM)
Compatibilité avec les principaux modèles de langage et modèles multimodaux de grande taille du marché, vous permettant de mettre en œuvre le modèle idéal pour chaque besoin métier.

Intégration au niveau de l'API
Connectez le serveur d'inférence directement à vos systèmes et flux de travail Skyone Studio via des API sécurisées, facilitant ainsi l'automatisation et le développement de solutions.
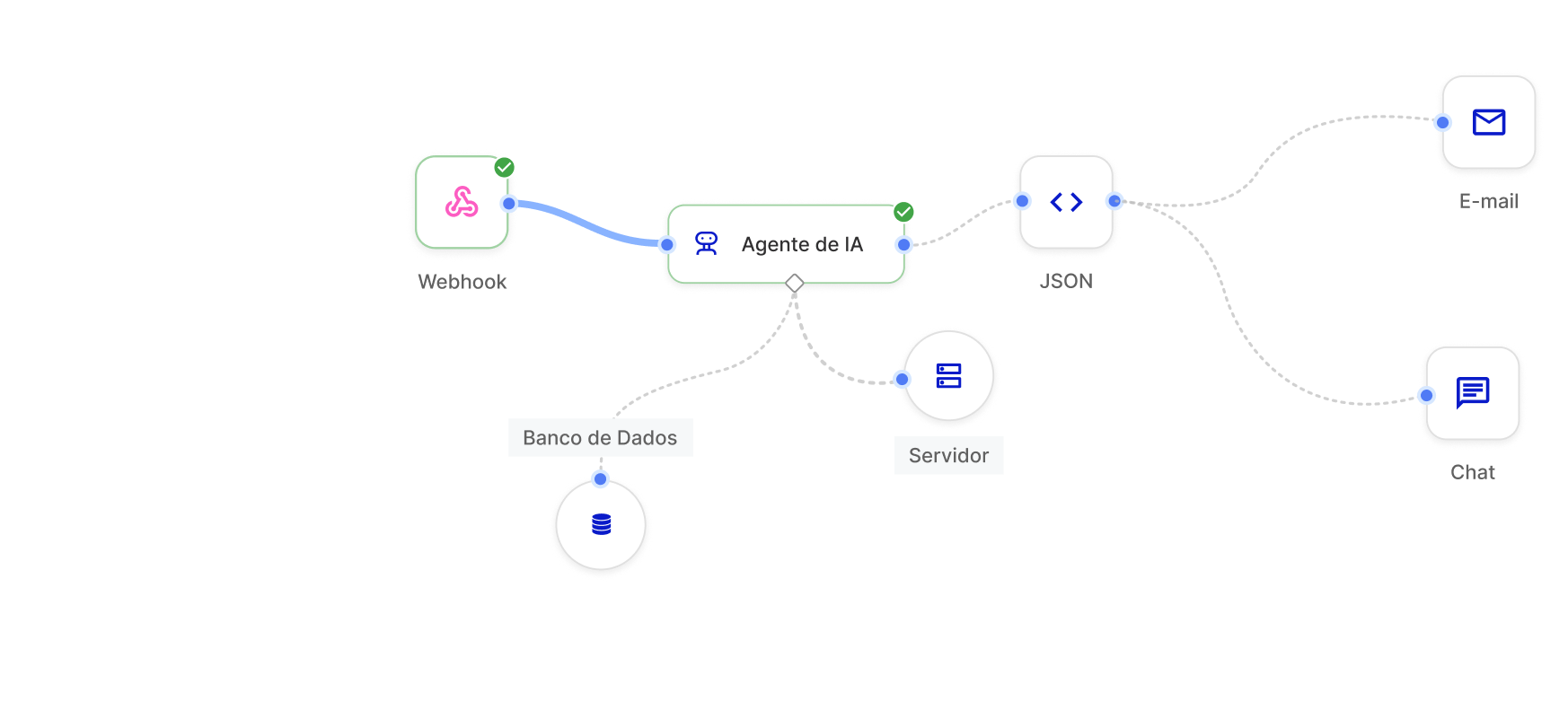
Tokenisation optimisée
Gérez et optimisez l'utilisation des jetons (coût et unités de traitement en LLM), en veillant à ce que la consommation des ressources soit efficace et conforme à votre budget.
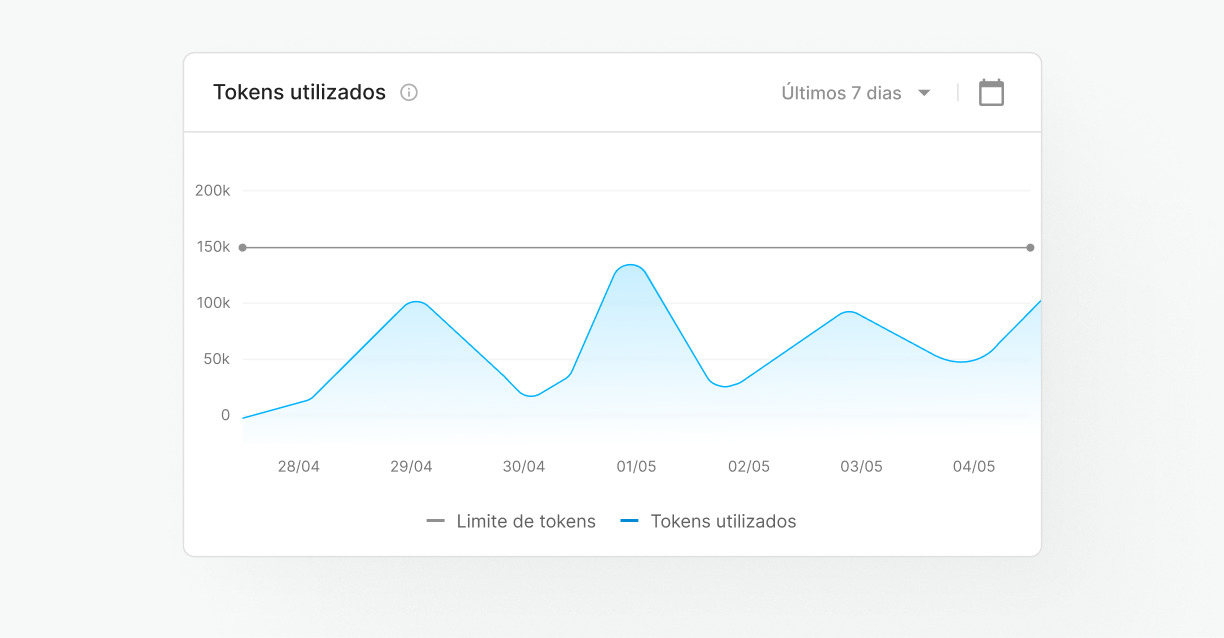
Gestion centralisée
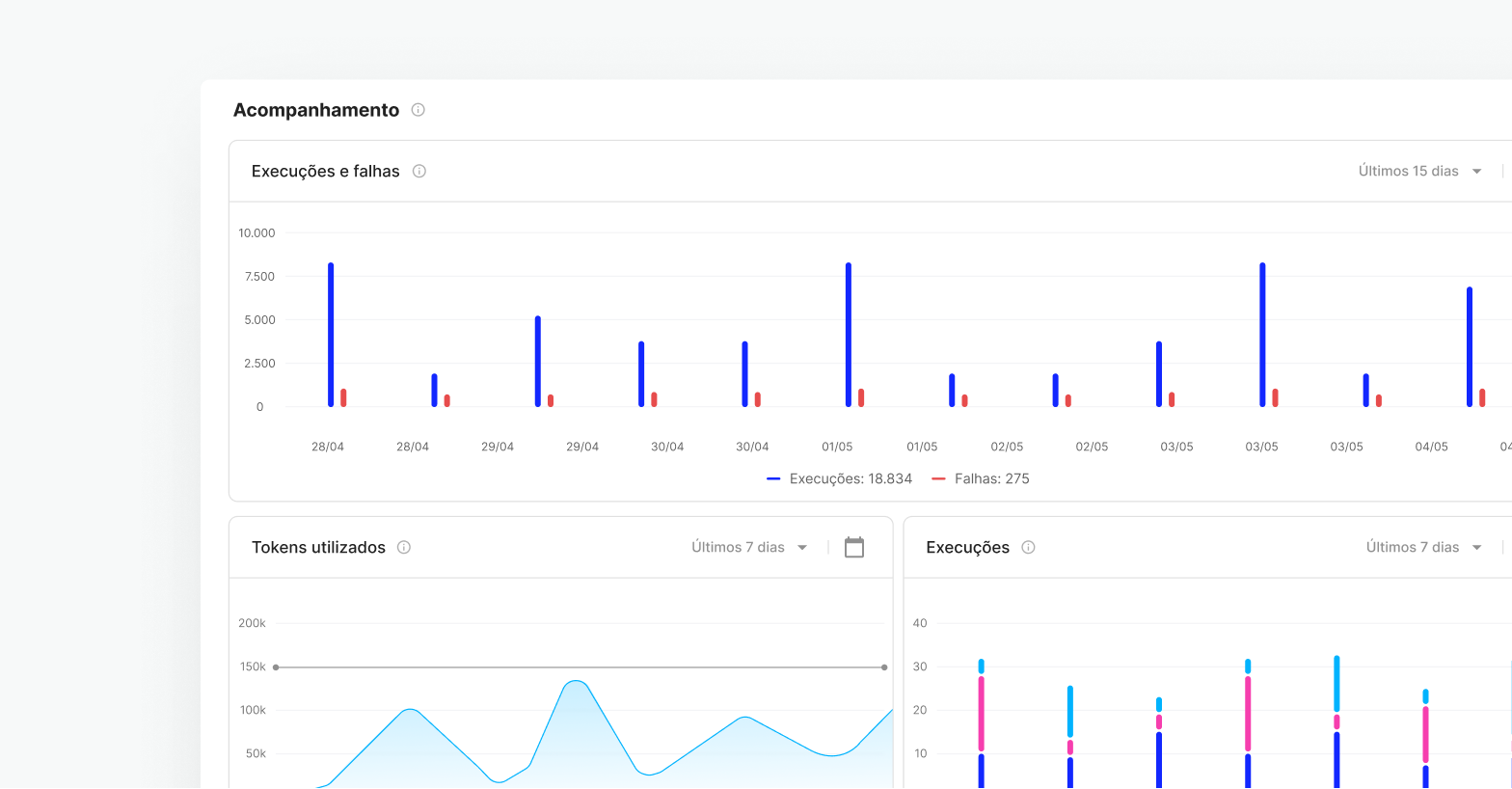
Configurez et surveillez les performances de votre serveur et l'utilisation de vos modèles dans un environnement unique, Skyone Studio, simplifiant ainsi la gestion et le dépannage de vos opérations d'IA.
Consultez la foire aux questions. Pour plus d'informations, veuillez nous contacter.