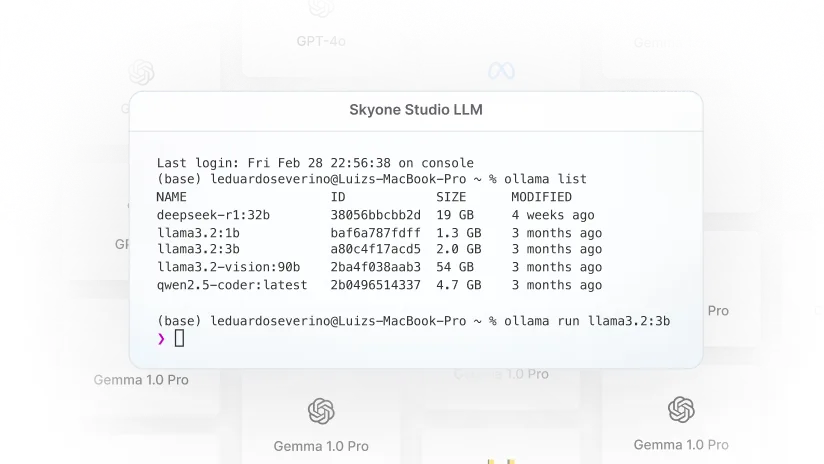
Servidor de inferencia
Ejecute modelos de IA en producción con alto rendimiento y escalabilidad. El Servidor de Inferencia de Skyone ofrece un entorno dedicado y optimizado que garantiza agilidad y eficiencia para su Fábrica de IA.
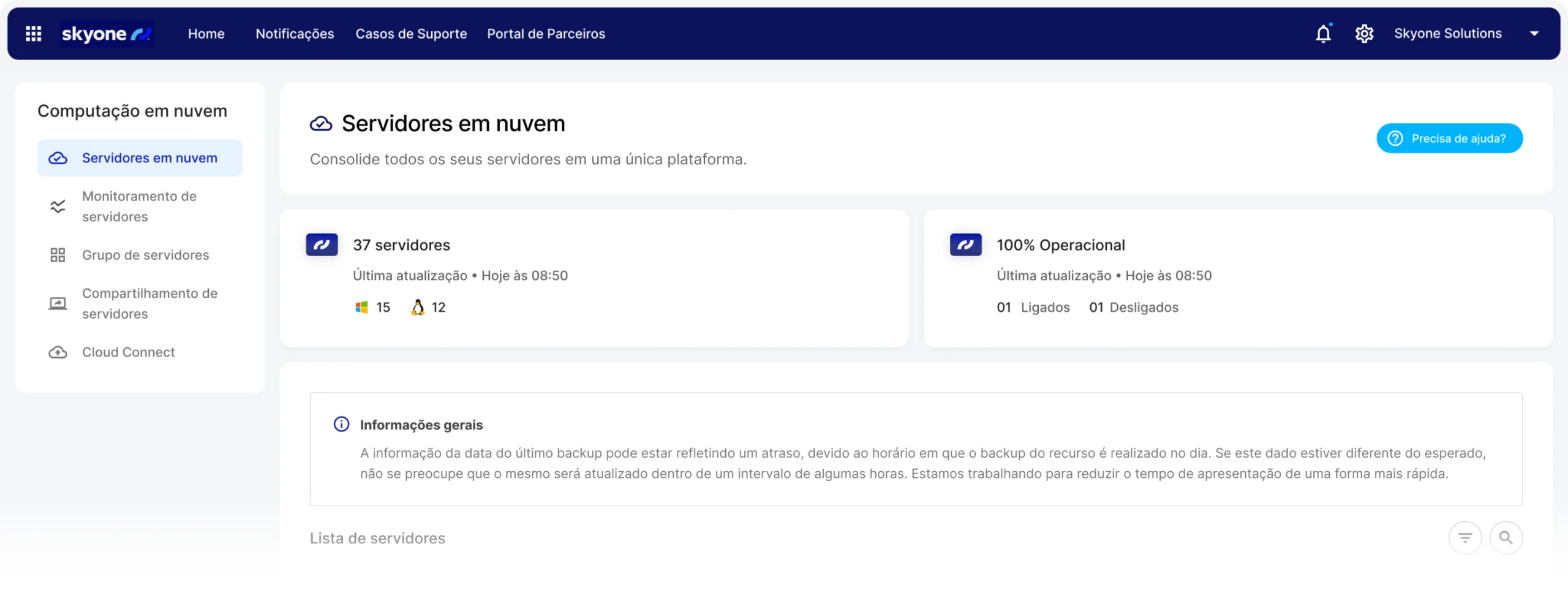
Lo que tu empresa necesita para crecer
Rendimiento optimizado con GPU y LLM
Utilice una infraestructura de GPU dedicada y optimizada para el procesamiento de modelos de lenguaje (LLM), como LLAMA 3 y Gemini 1.5 Pro. Esto garantiza que las tareas de IA y los agentes autónomos se ejecuten con alto rendimiento y mínima latencia, esencial para aplicaciones en tiempo real.
Escalabilidad bajo demanda
Su fábrica de IA crece sin cuellos de botella. El Servidor de Inferencia se integra con la infraestructura de Skyone para ofrecer escalabilidad a medida que cambian las demandas de uso. Esto significa que puede aumentar o disminuir los recursos de procesamiento, optimizando costos y manteniendo la productividad sin desperdicios.
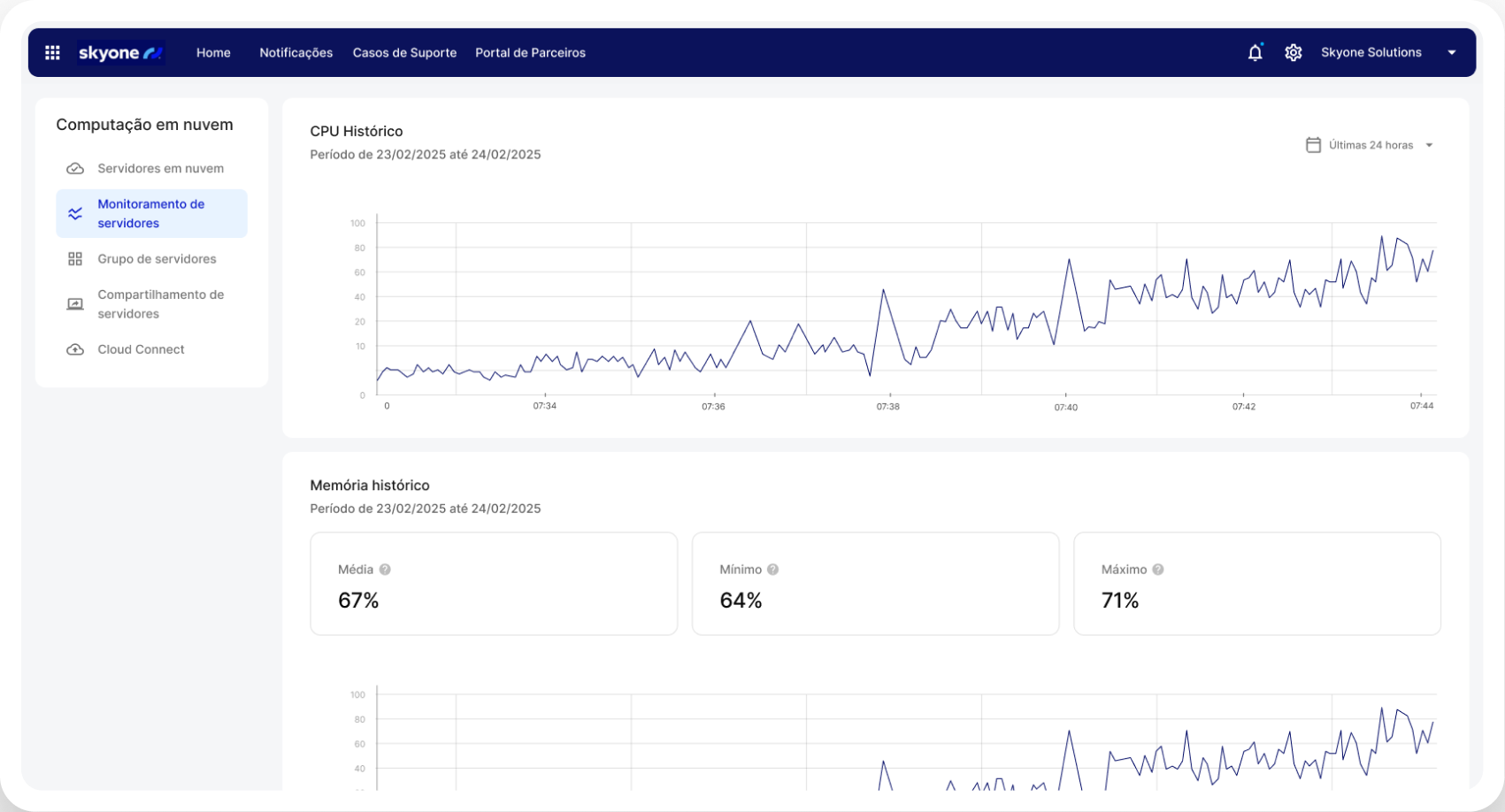
Control completo de costes por uso
Logre previsibilidad y eficiencia financiera. Al usar servidores optimizados, solo paga por el volumen de procesamiento (GPU) y los recursos utilizados. Esto es crucial para las operaciones financieras con IA, ya que permite una innovación viable y un claro retorno de la inversión (ROI).
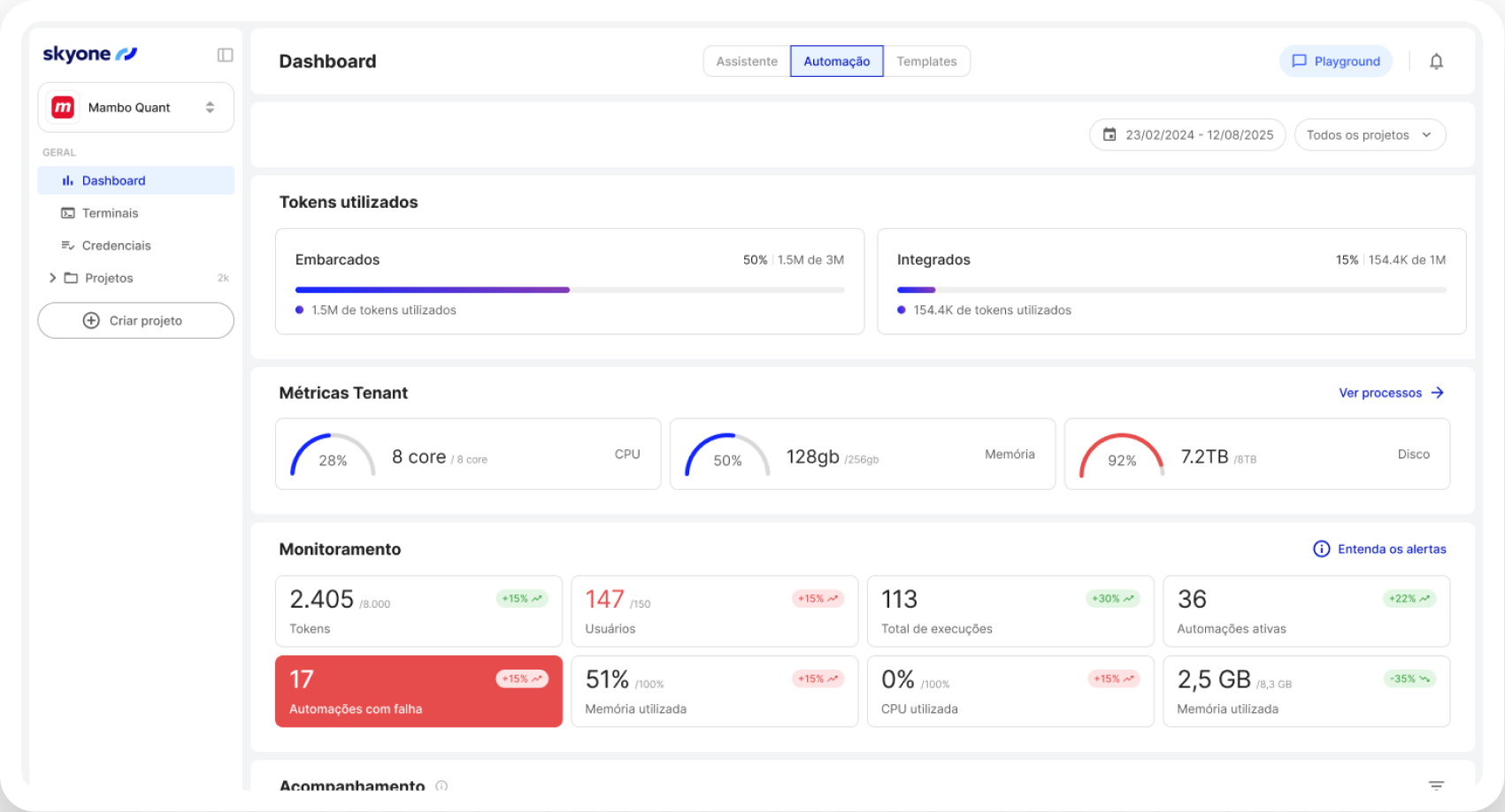
Cómo funciona
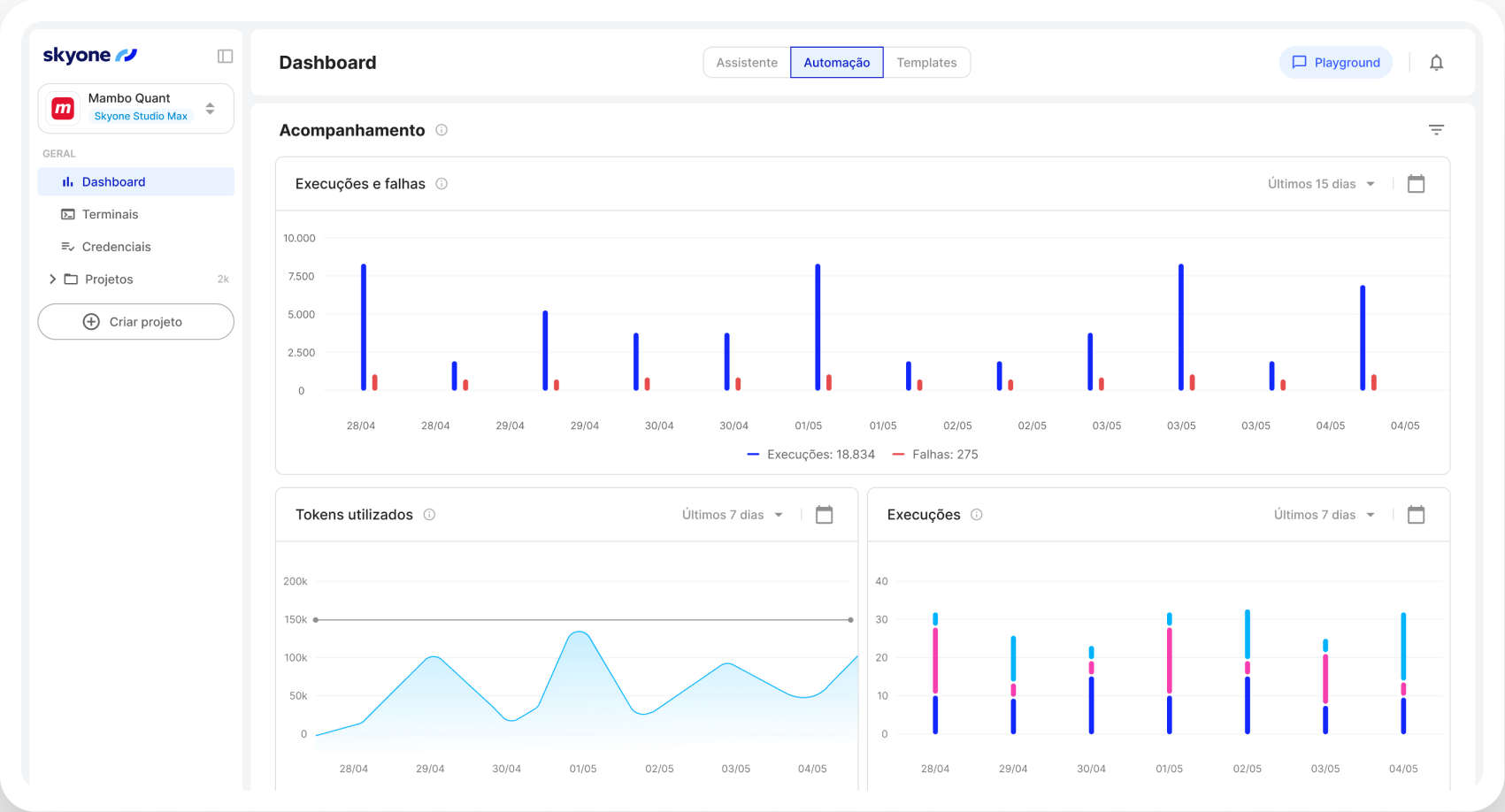
El servidor de inferencia ejecuta modelos de IA en Skyone Studio con alto rendimiento, lo que garantiza respuestas rápidas y eficientes para las aplicaciones comerciales después del entrenamiento o la selección del modelo.
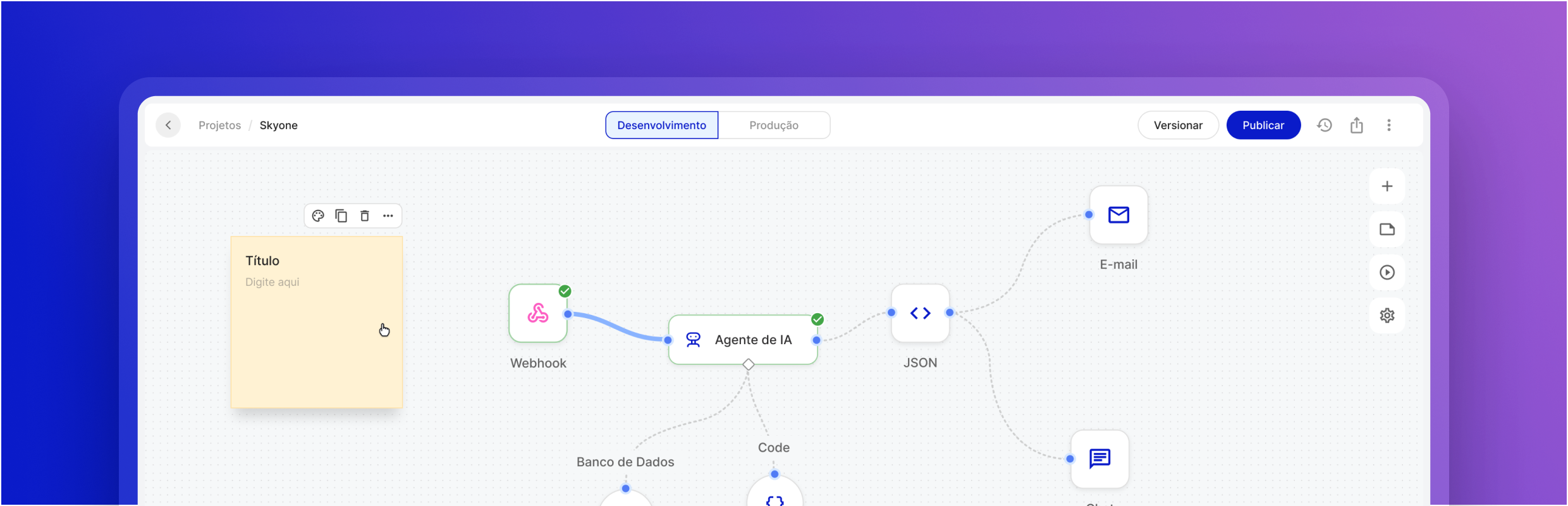
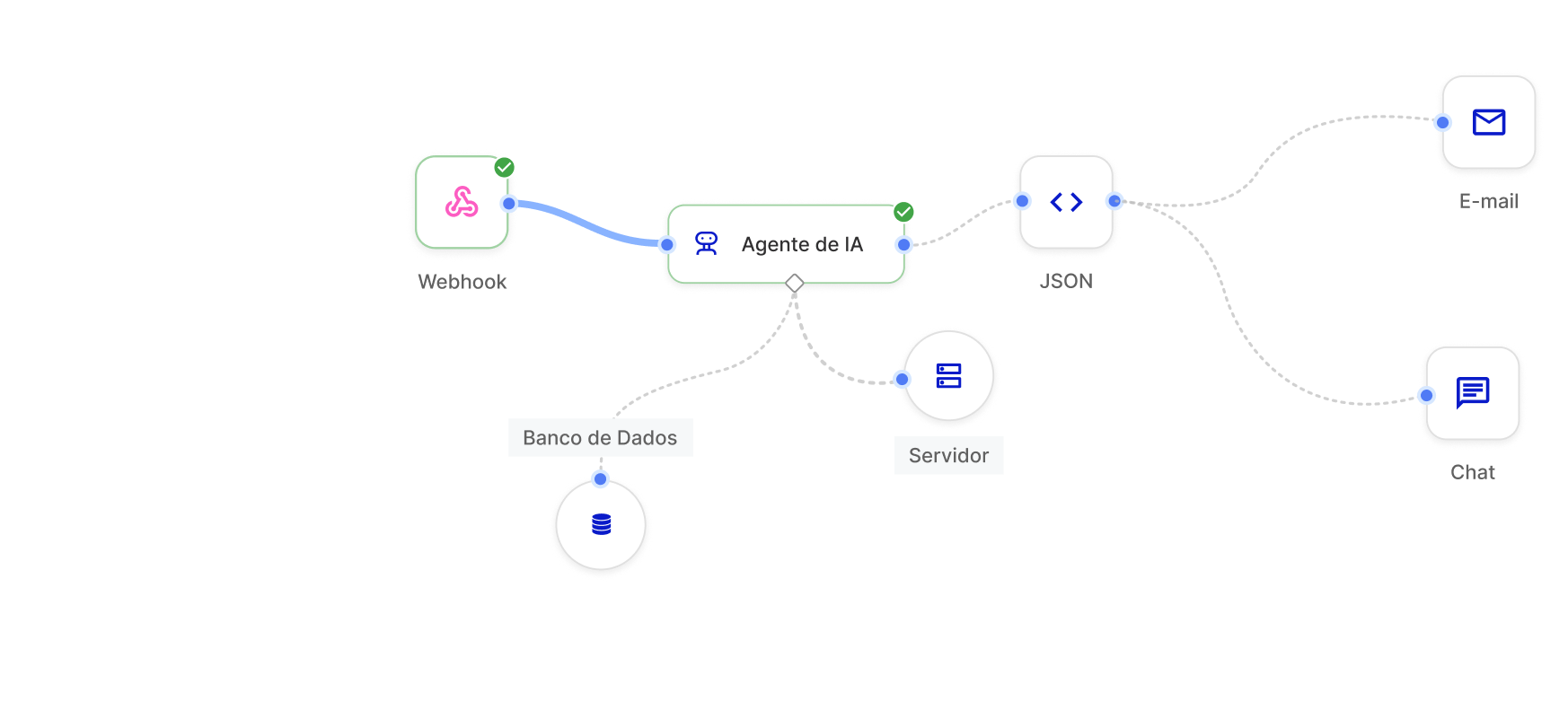
Optimice su negocio con Inference Server
Soporte para múltiples modelos (LLM/LMM)
Compatibilidad con los principales Grandes Modelos de Lenguaje y Grandes Modelos Multimodales del mercado, permitiendo implementar el modelo ideal para cada necesidad de negocio.

Integración a nivel de API
Conecte el servidor de inferencia directamente a sus sistemas y flujos de trabajo de Skyone Studio a través de API seguras, lo que facilita la automatización y el desarrollo de soluciones.
Tokenización optimizada
Gestiona y optimiza el uso de tokens (unidades de costo y procesamiento en LLMs), asegurando que el consumo de recursos sea eficiente y alineado con tu presupuesto.
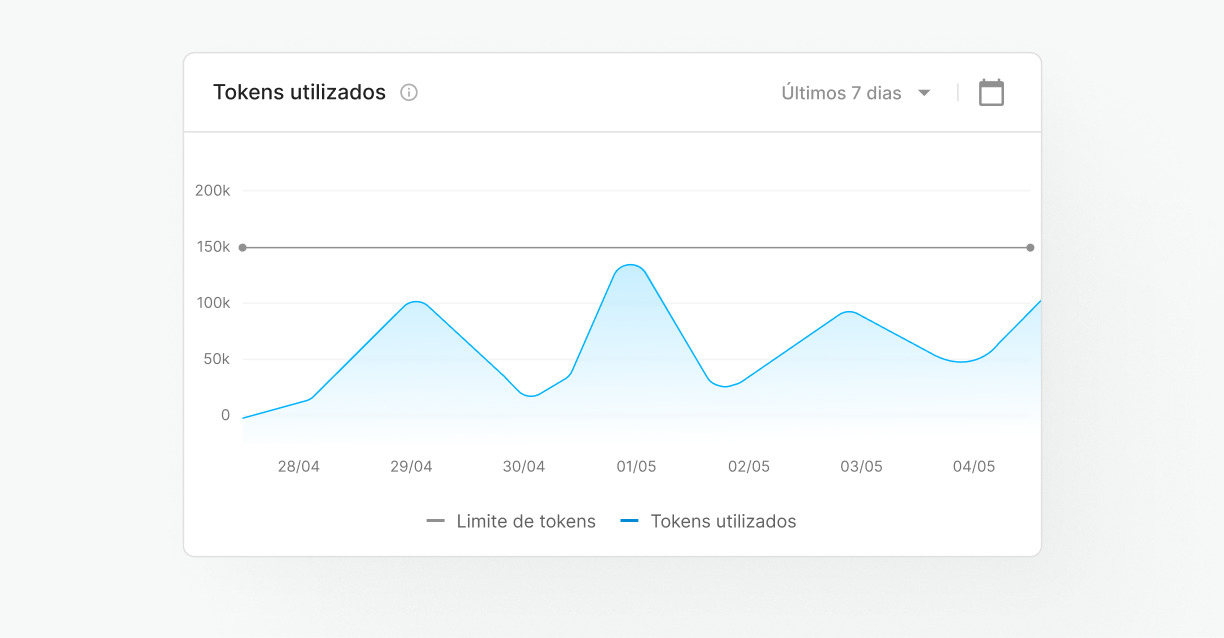
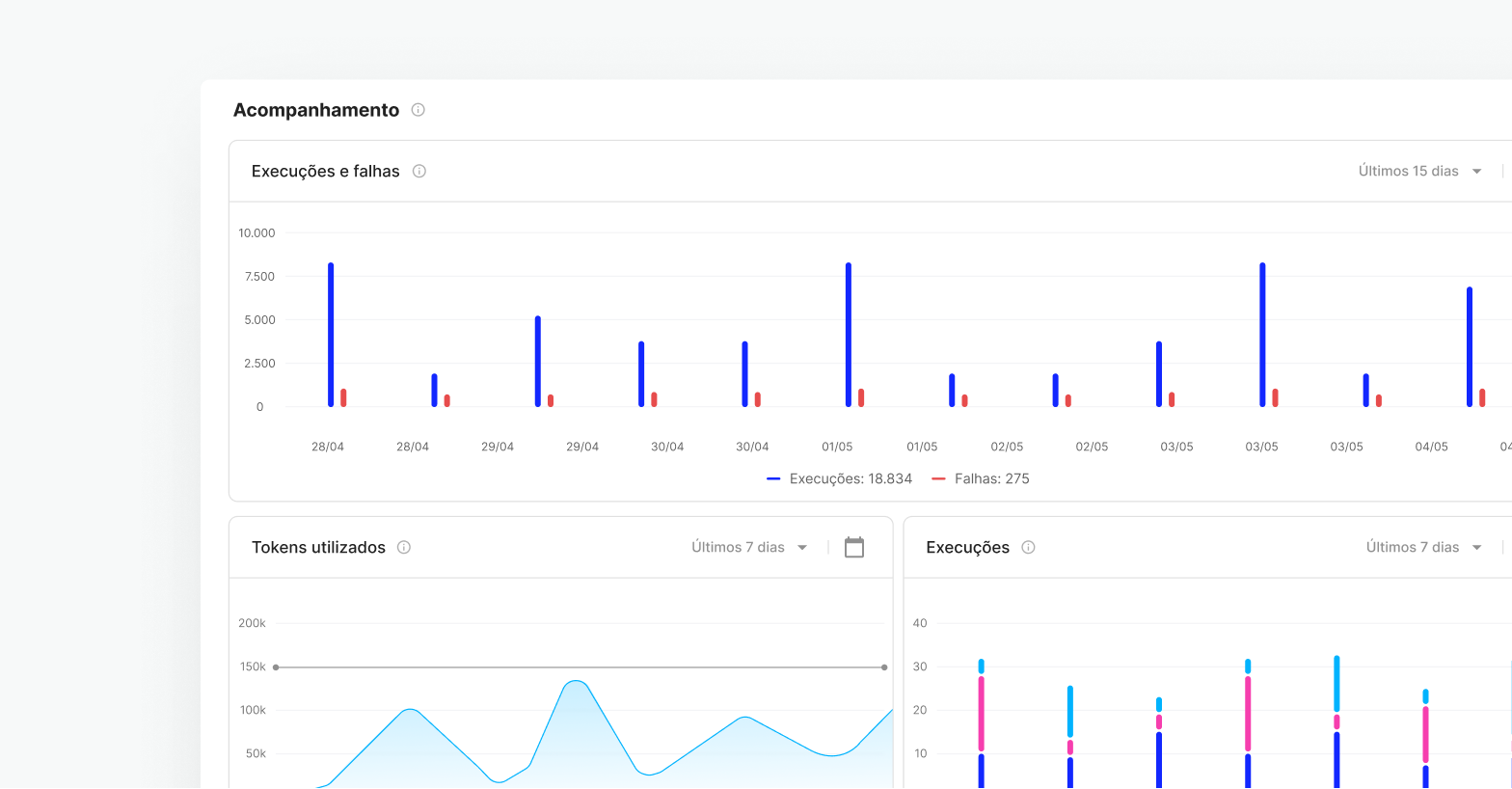
Gestión centralizada
Configure y monitoree el rendimiento de su servidor y el uso del modelo en un solo entorno, Skyone Studio, simplificando la administración y la resolución de problemas de su operación de IA.
Consulte las preguntas frecuentes. Si necesita más información, contáctenos.