Inference server
Run AI models in production with high performance and scalability. Skyone's Inference Server offers a dedicated and optimized environment, ensuring agility and efficiency for your AI Factory.
What your company needs to grow
Optimized performance with GPU and LLM
Utilize dedicated and optimized GPU infrastructure for Language Model Processing (LLMs), such as LLAMA 3 and Gemini 1.5 Pro. This ensures that AI tasks and autonomous agents execute with high performance and minimal latency, essential for real-time applications.
Scalability on demand
Your AI Factory grows without bottlenecks. The Inference Server integrates with Skyone's infrastructure to provide scalability as usage demands change. This means you can increase or decrease processing resources, optimizing costs and maintaining productivity without waste.
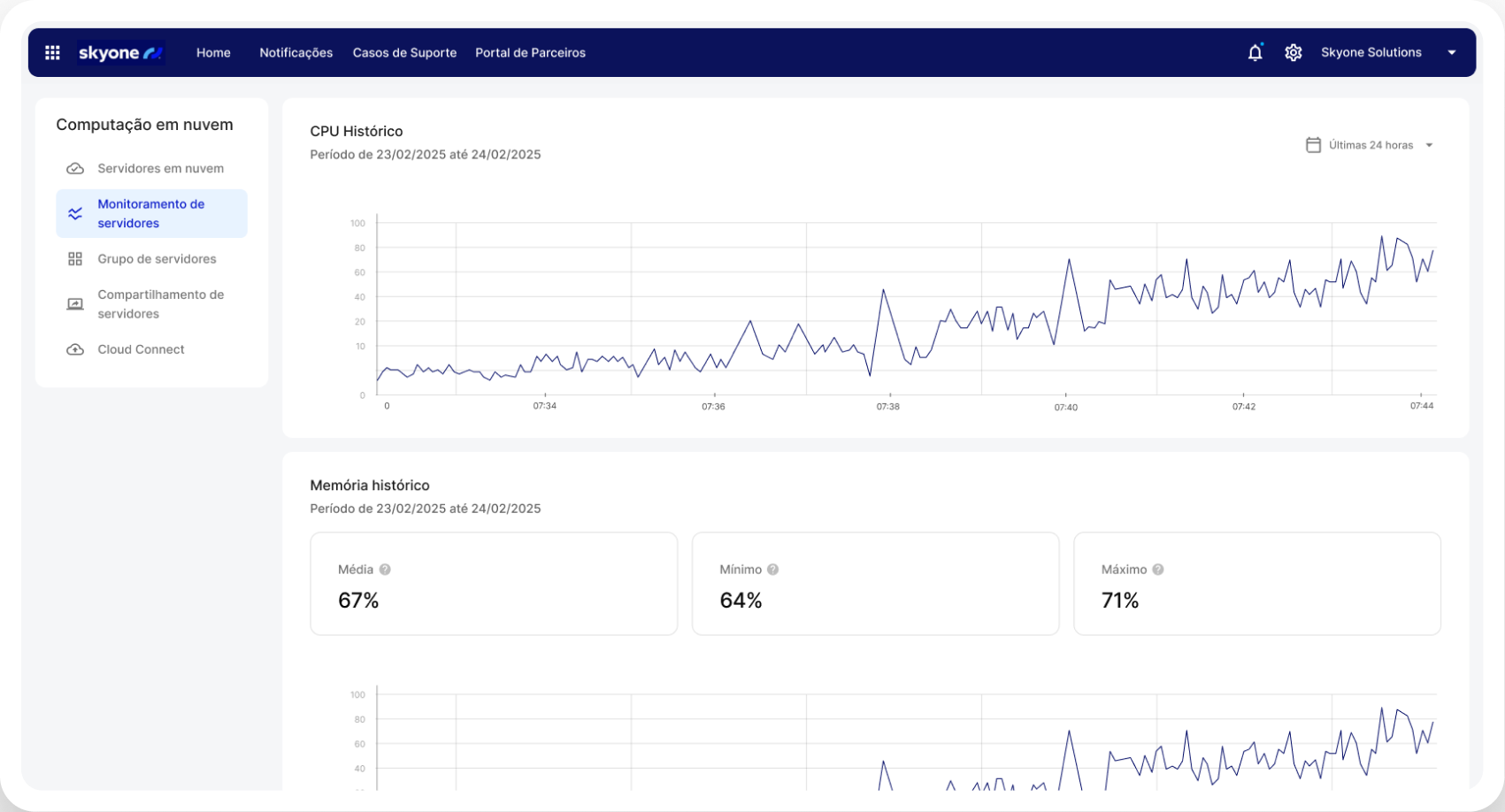
Complete cost control by usage
Achieve predictability and financial efficiency. By using optimized servers, you only pay for the processing volume (GPU) and resources used. This is crucial for AI FinOps, enabling viable innovation and a clear return on investment (ROI).
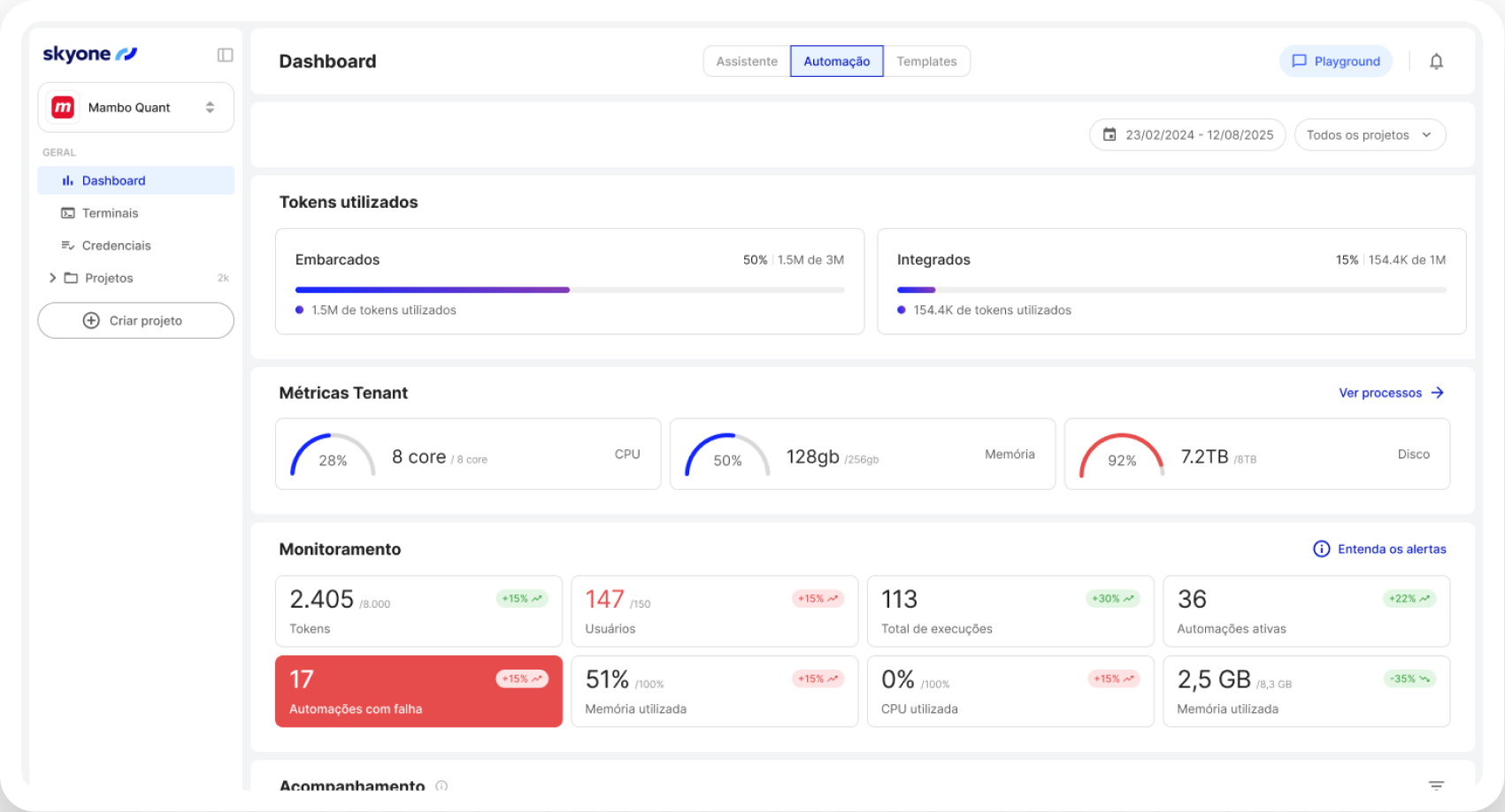
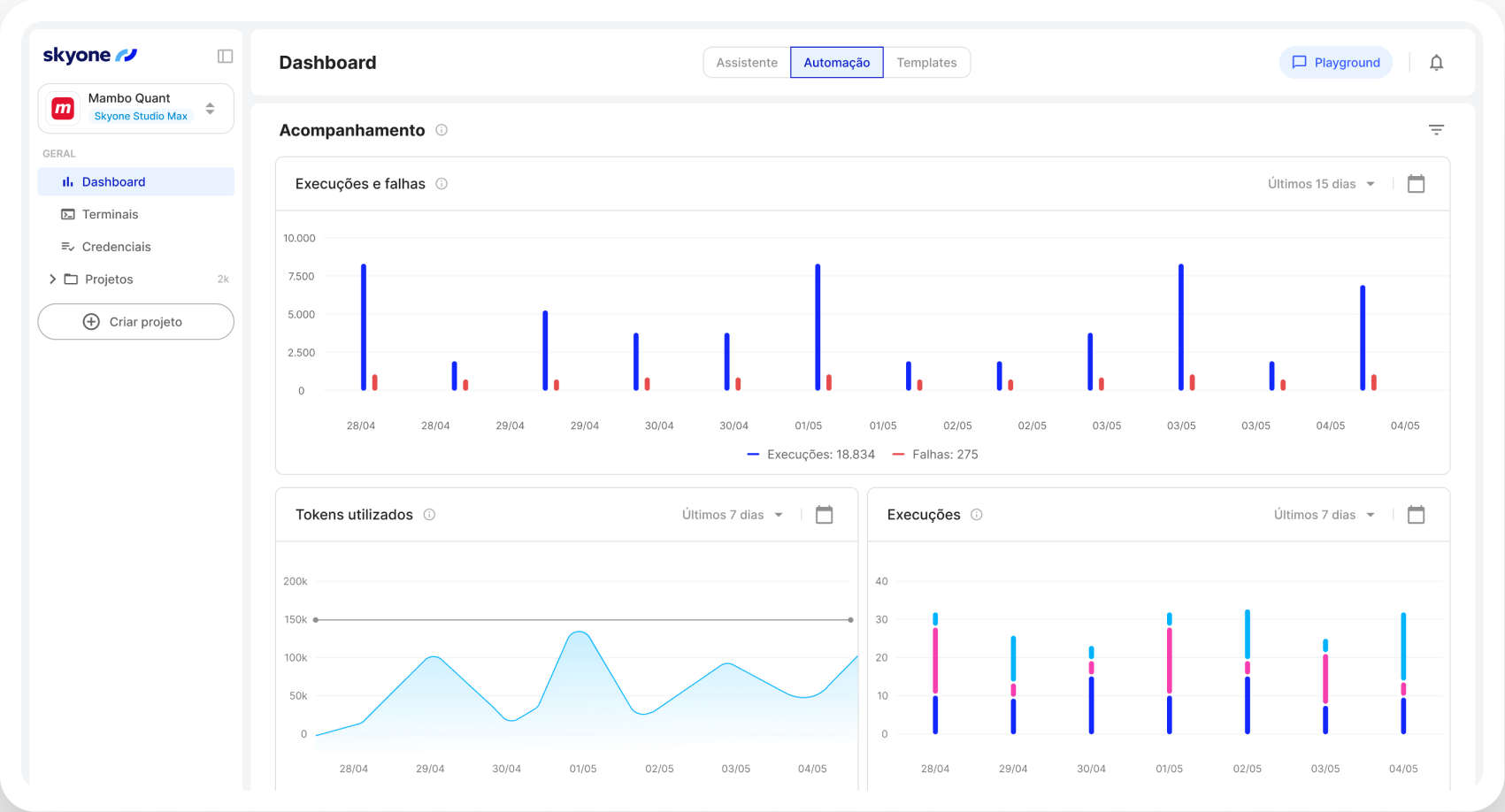
How it works
The Inference Server runs AI models in Skyone Studio with high performance, ensuring fast and efficient responses for business applications after model training or selection.
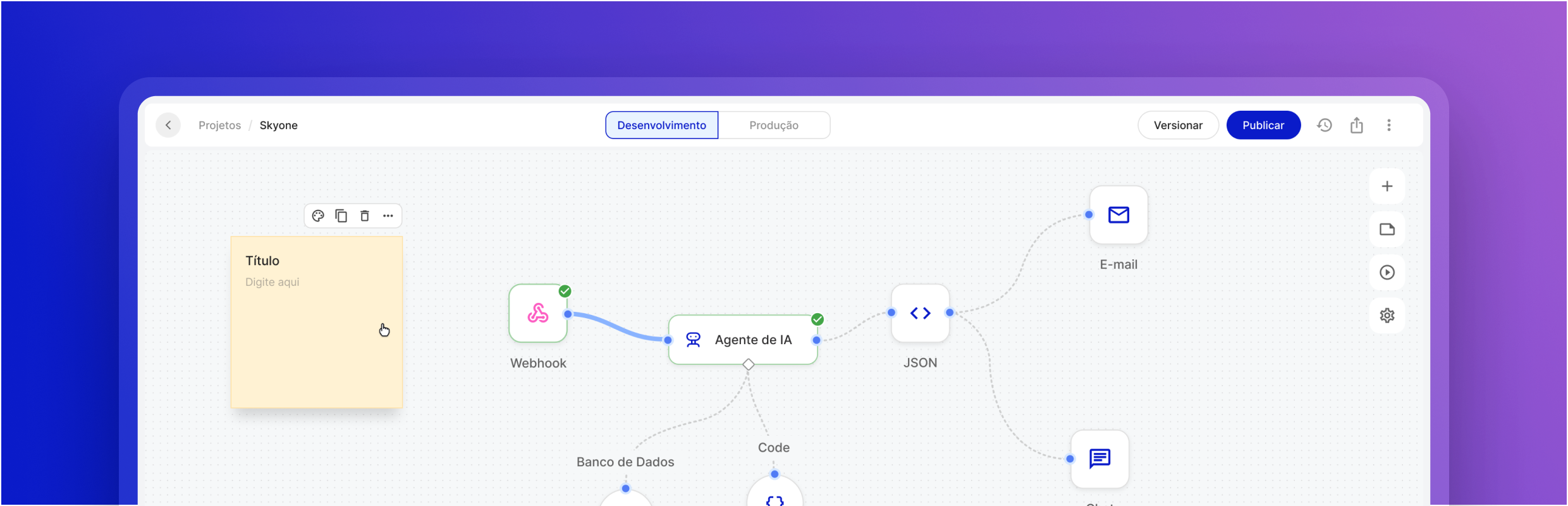
Optimize your business with the Inference Server
Support for multiple models (LLM/LMM)
Compatibility with the leading Large Language Models and Large Multimodal Models on the market, allowing you to implement the ideal model for each business need.

API-level integration
Connect the Inference Server directly to your Skyone Studio systems and workflows via secure APIs, facilitating automation and solution development.
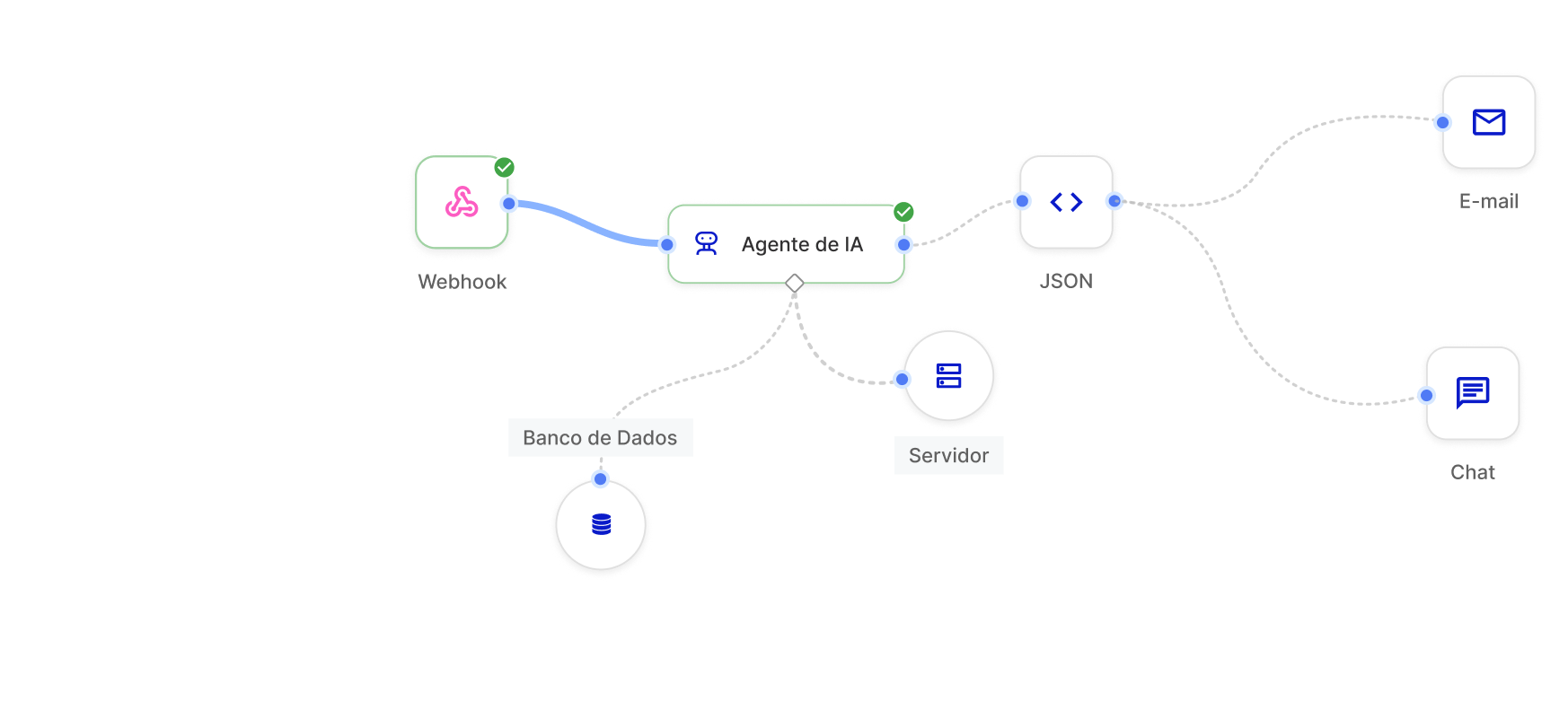
Optimized Tokenization
Manage and optimize the use of tokens (cost and processing units in LLMs), ensuring that resource consumption is efficient and aligned with your budget.
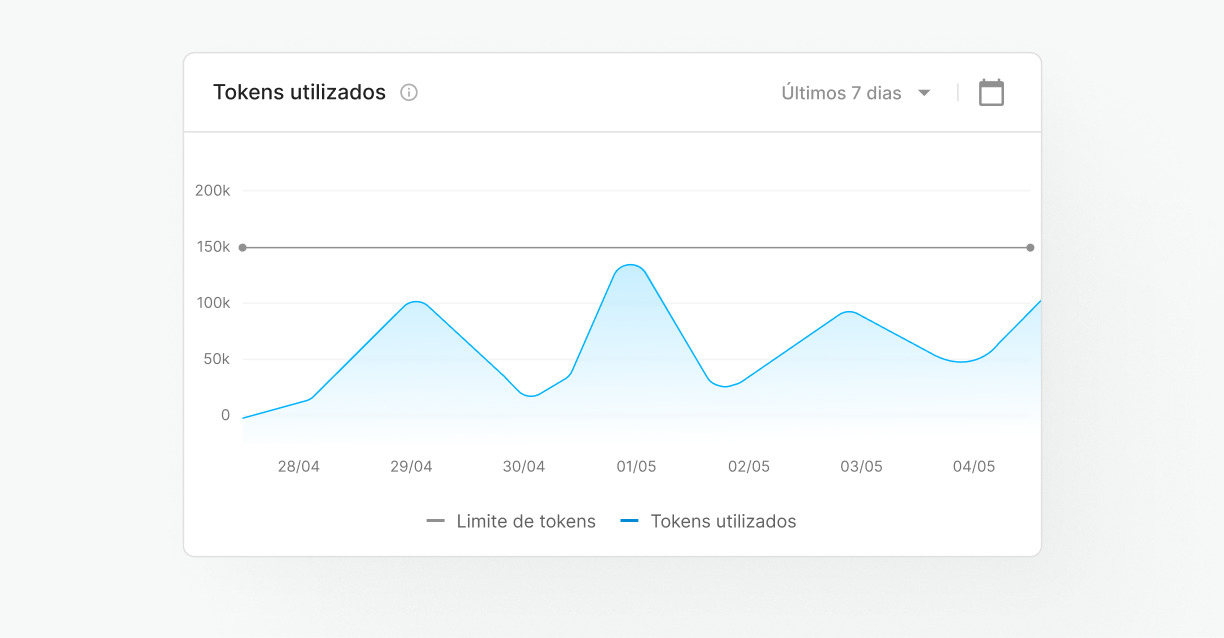
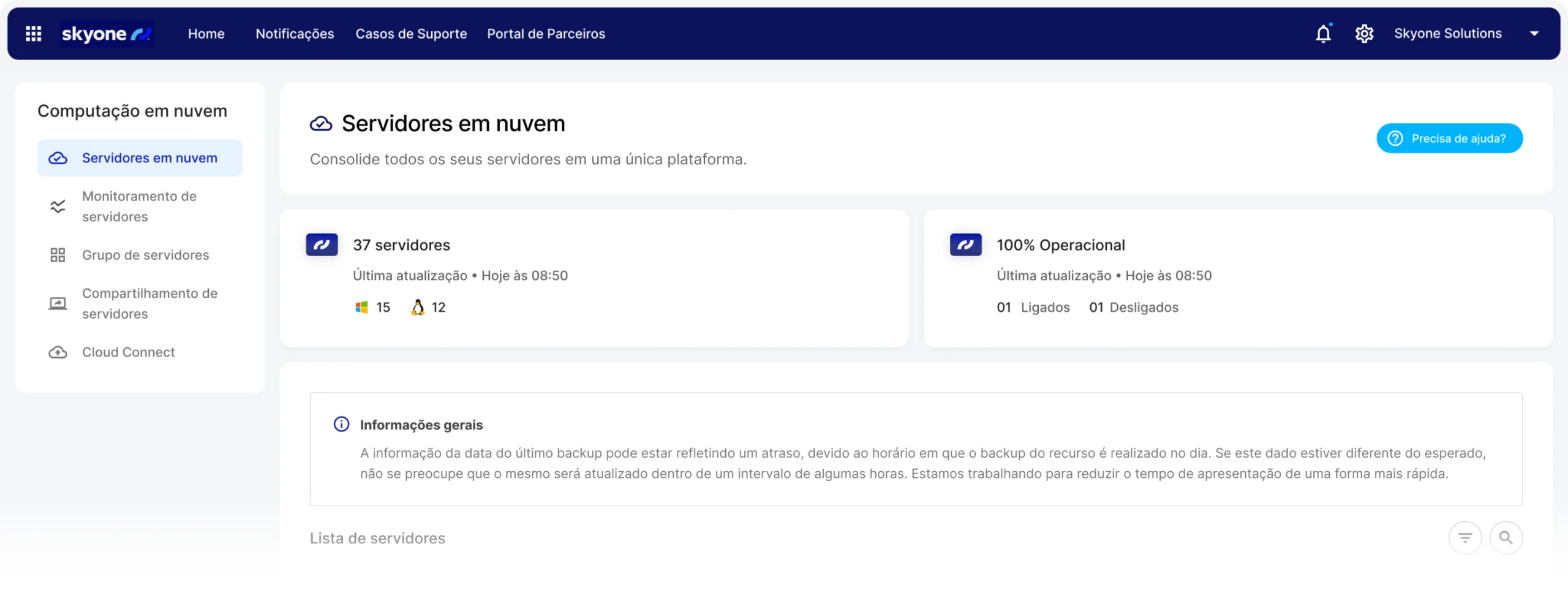
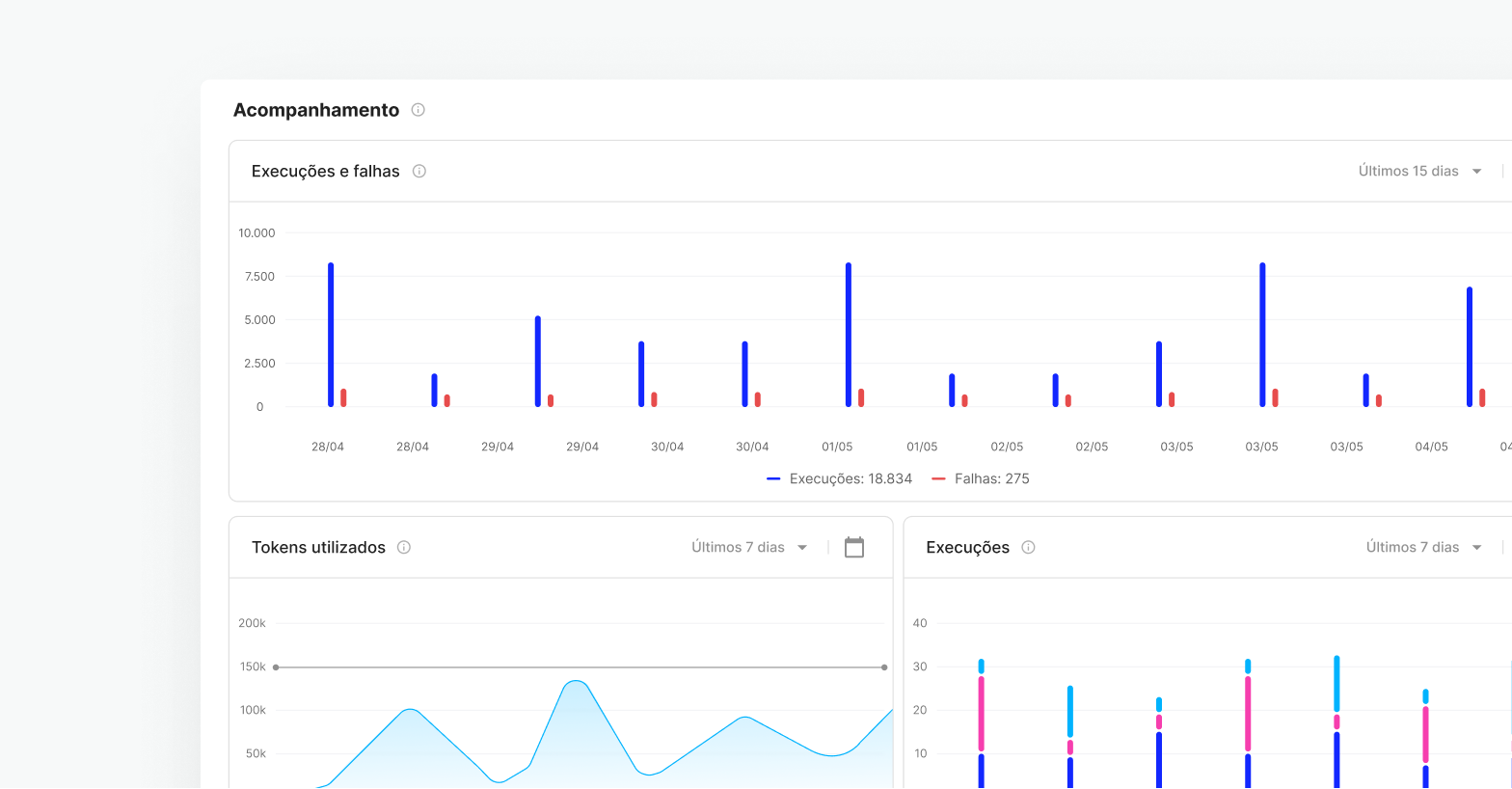
Centralized management
Configure and monitor your server performance and model usage in a single environment, Skyone Studio, simplifying the management and troubleshooting of your AI operation.
See the frequently asked questions. If you need more information, please contact us.