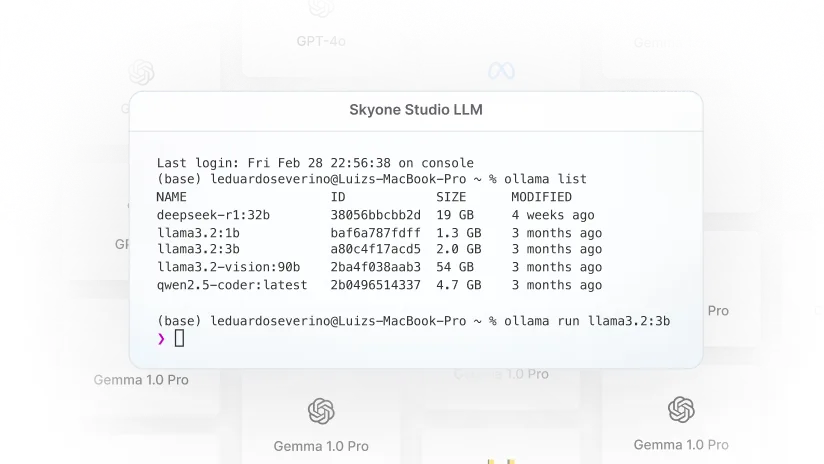
Servidor de inferência
Execute modelos de IA em produção com alto desempenho e escalabilidade. O Servidor de Inferência da Skyone oferece um ambiente dedicado e otimizado, garantindo agilidade e eficiência para sua AI Factory.
O que sua empresa precisa para crescer
Desempenho otimizado com GPU e LLM
Utilize infraestrutura de GPU dedicada e otimizada para o processamento de modelos de linguagem (LLMs), como LLAMA 3 e Gemini 1.5 Pro. Isso garante que a execução das tarefas de IA e dos agentes autônomos ocorra com alta performance e latência mínima, essenciais para aplicações em tempo real.
Escalabilidade sob demanda
Sua AI Factory cresce sem gargalos. O Servidor de Inferência se integra à infraestrutura da Skyone para oferecer escalabilidade conforme a demanda de uso. Isso significa que você pode aumentar ou diminuir os recursos de processamento, otimizando custos e mantendo a produtividade sem desperdício.
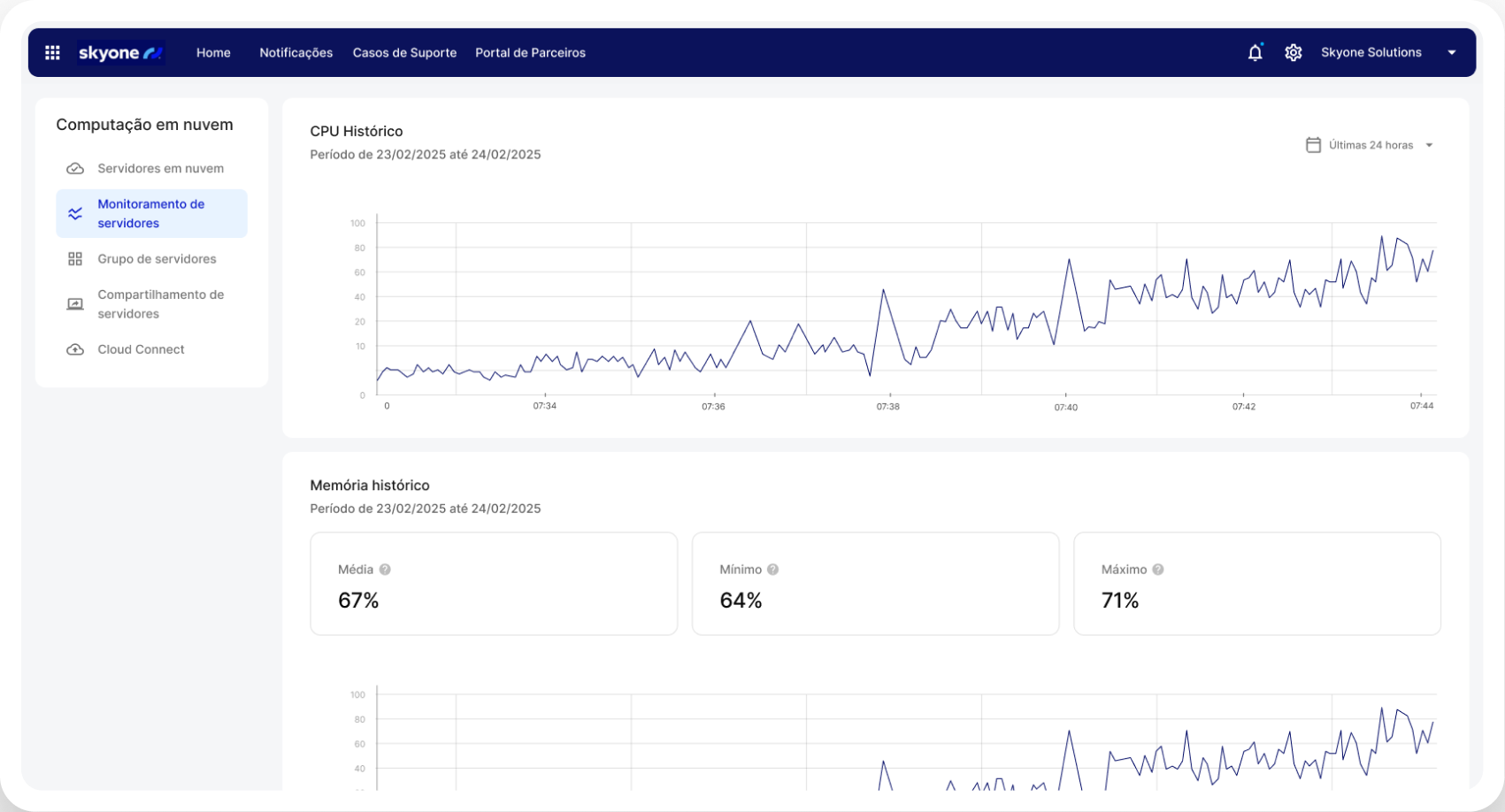
Controle total de custos por uso
Tenha previsibilidade e eficiência financeira. Ao utilizar servidores otimizados, você paga apenas pelo volume de processamento (GPU) e pelos recursos utilizados. Isso é crucial para o FinOps da IA, permitindo que a inovação seja viável e o retorno sobre o investimento (ROI) seja claro.
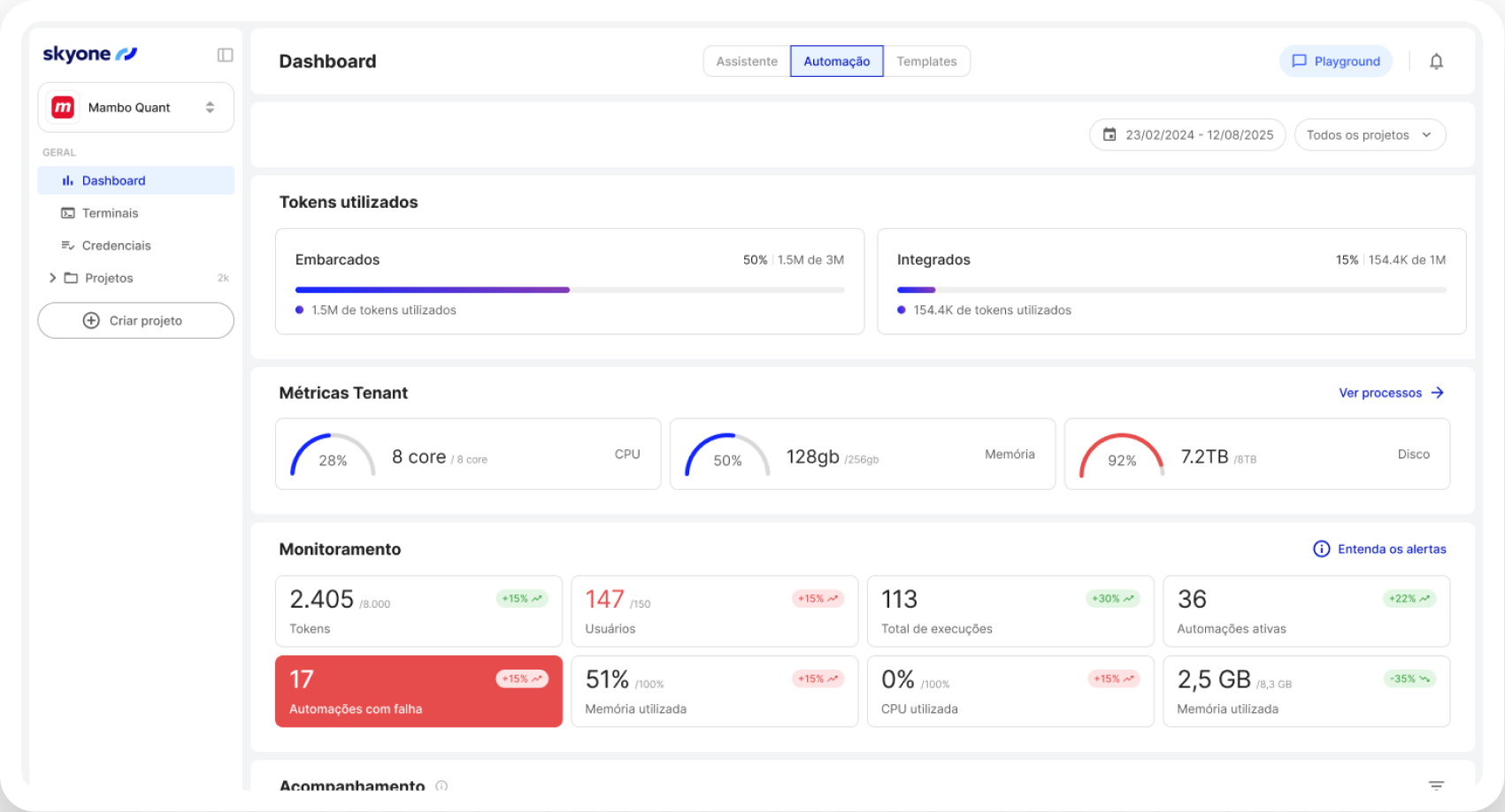
Como funciona
O Servidor de Inferência executa modelos de IA no Skyone Studio com alta performance, garantindo respostas rápidas e eficientes para aplicações de negócio após o treinamento ou escolha do modelo.
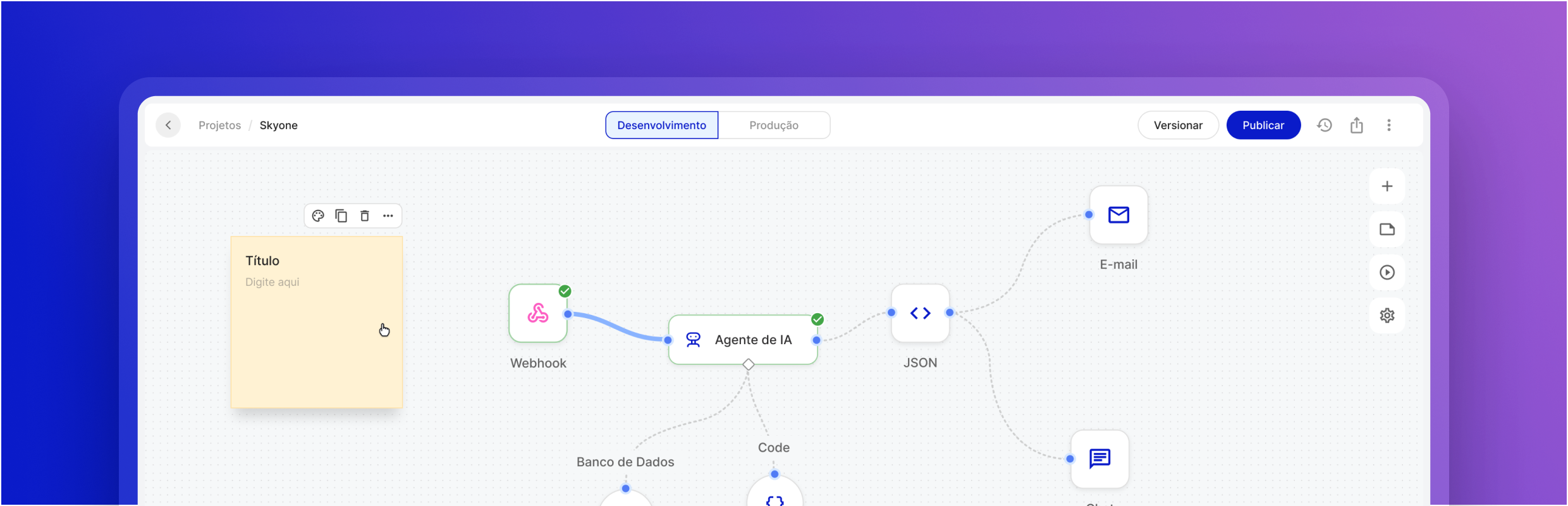
Otimize seu negócio com o Servidor de inferência
Suporte a modelos múltiplos (LLM/LMM)
Compatibilidade com os principais Large Language Models e Large Multimodal Models do mercado, permitindo que você execute o modelo ideal para cada necessidade de negócio.

Integração nível API
Conecte o Servidor de Inferência diretamente aos seus sistemas e fluxos de trabalho do Skyone Studio por meio de APIs seguras, facilitando a automação e o desenvolvimento de soluções.
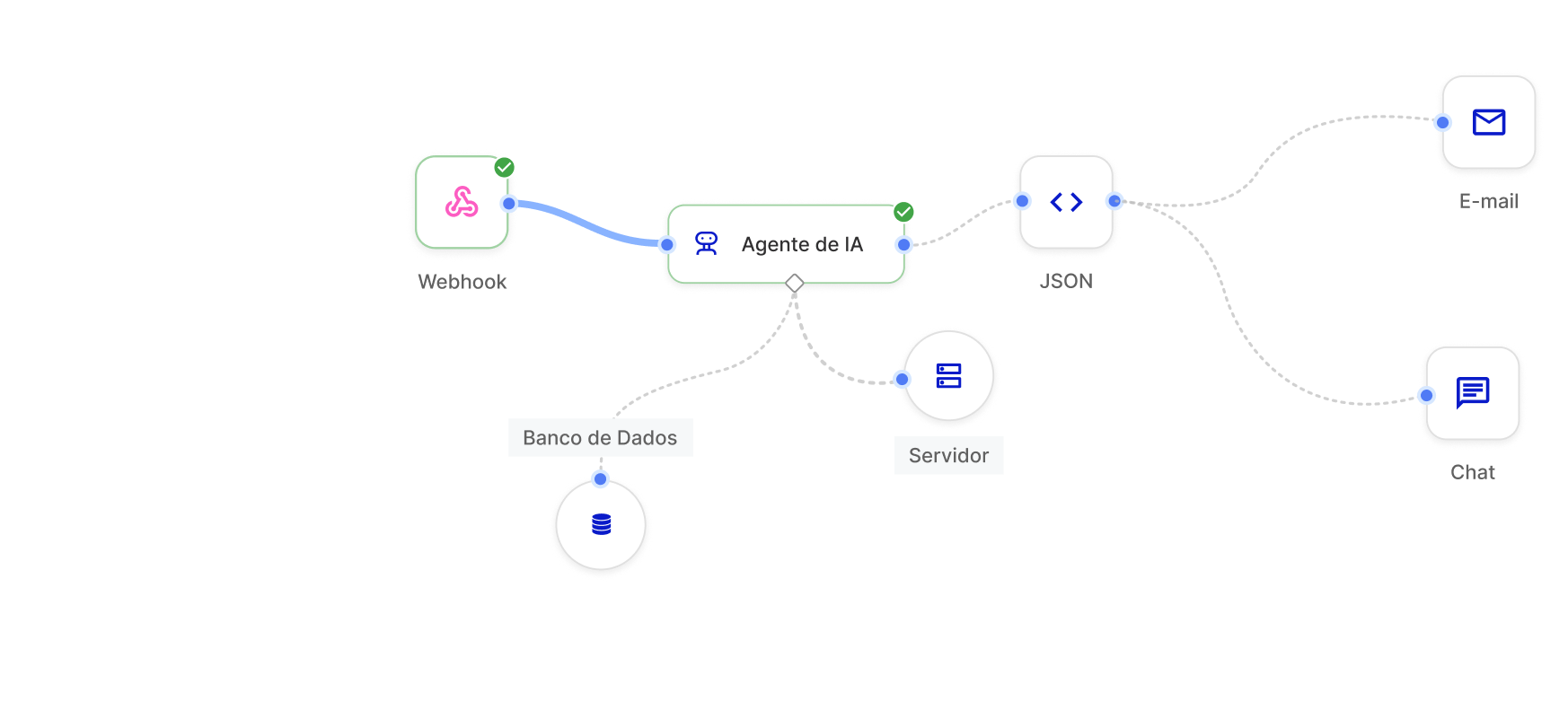
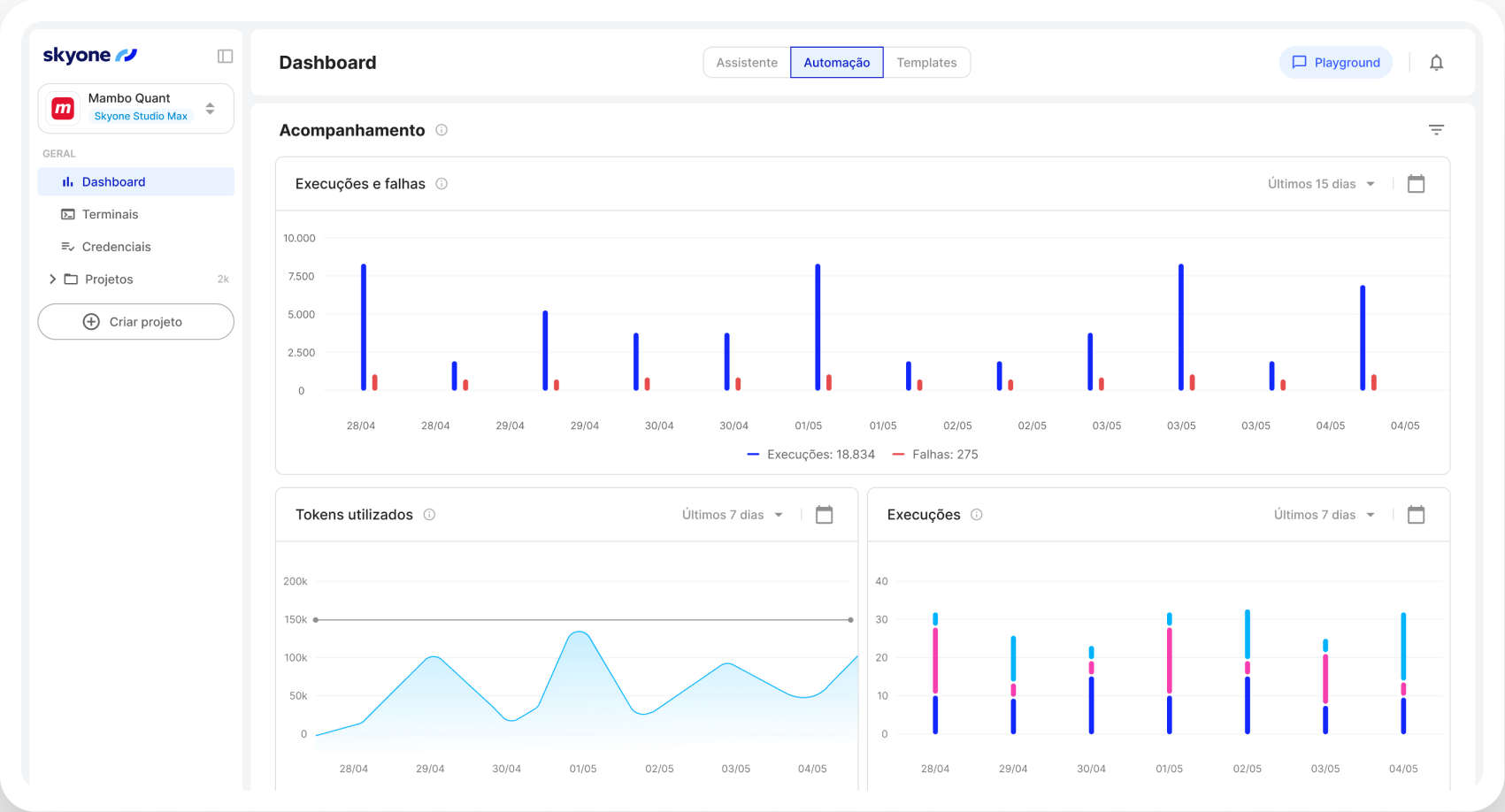
Tokenização otimizada
Gerencie e otimize o uso de tokens (unidades de custo e processamento em LLMs), garantindo que o consumo de recursos seja eficiente e alinhado ao seu orçamento.
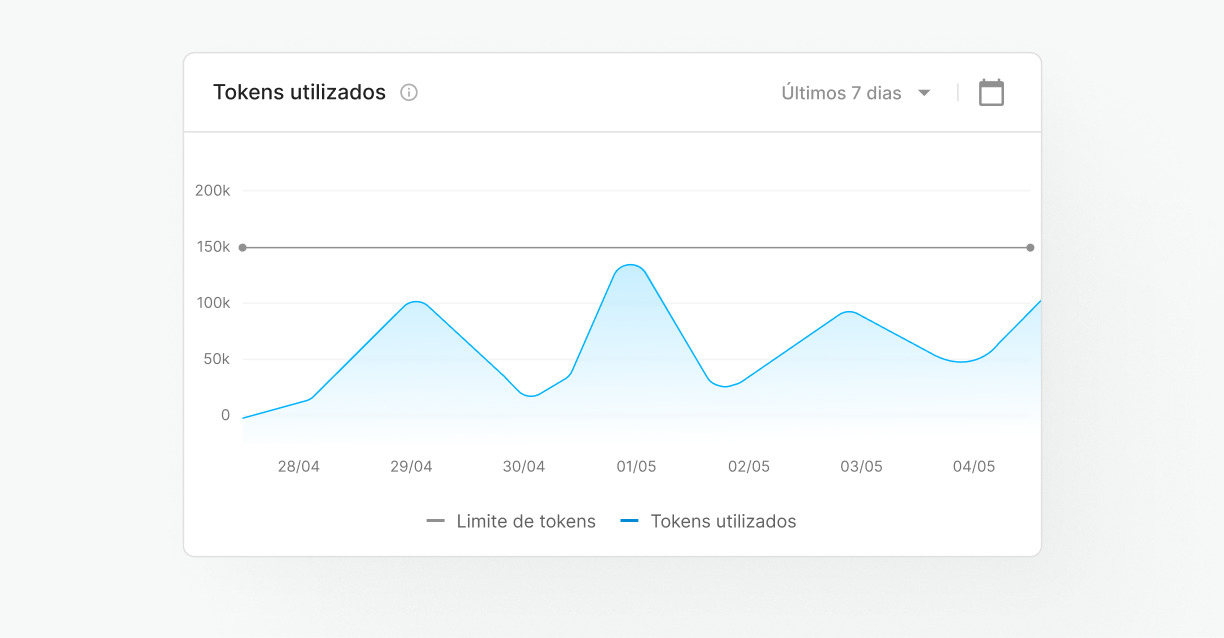
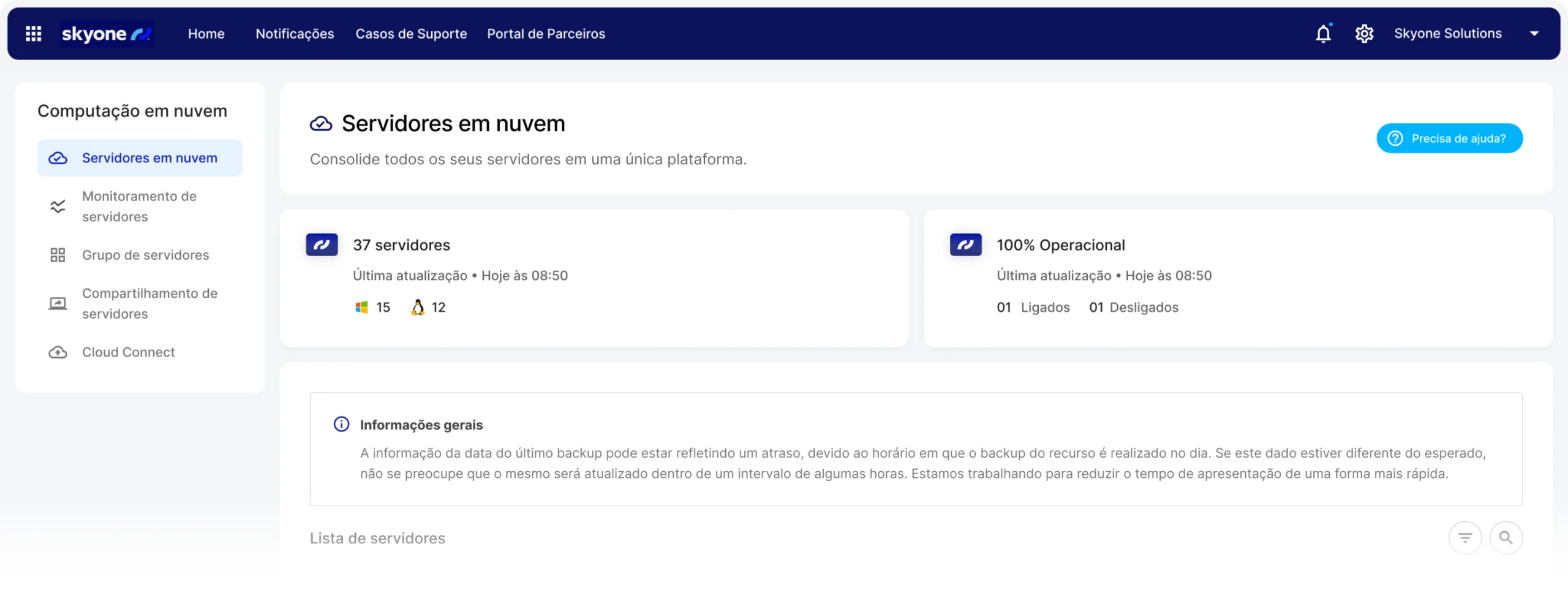
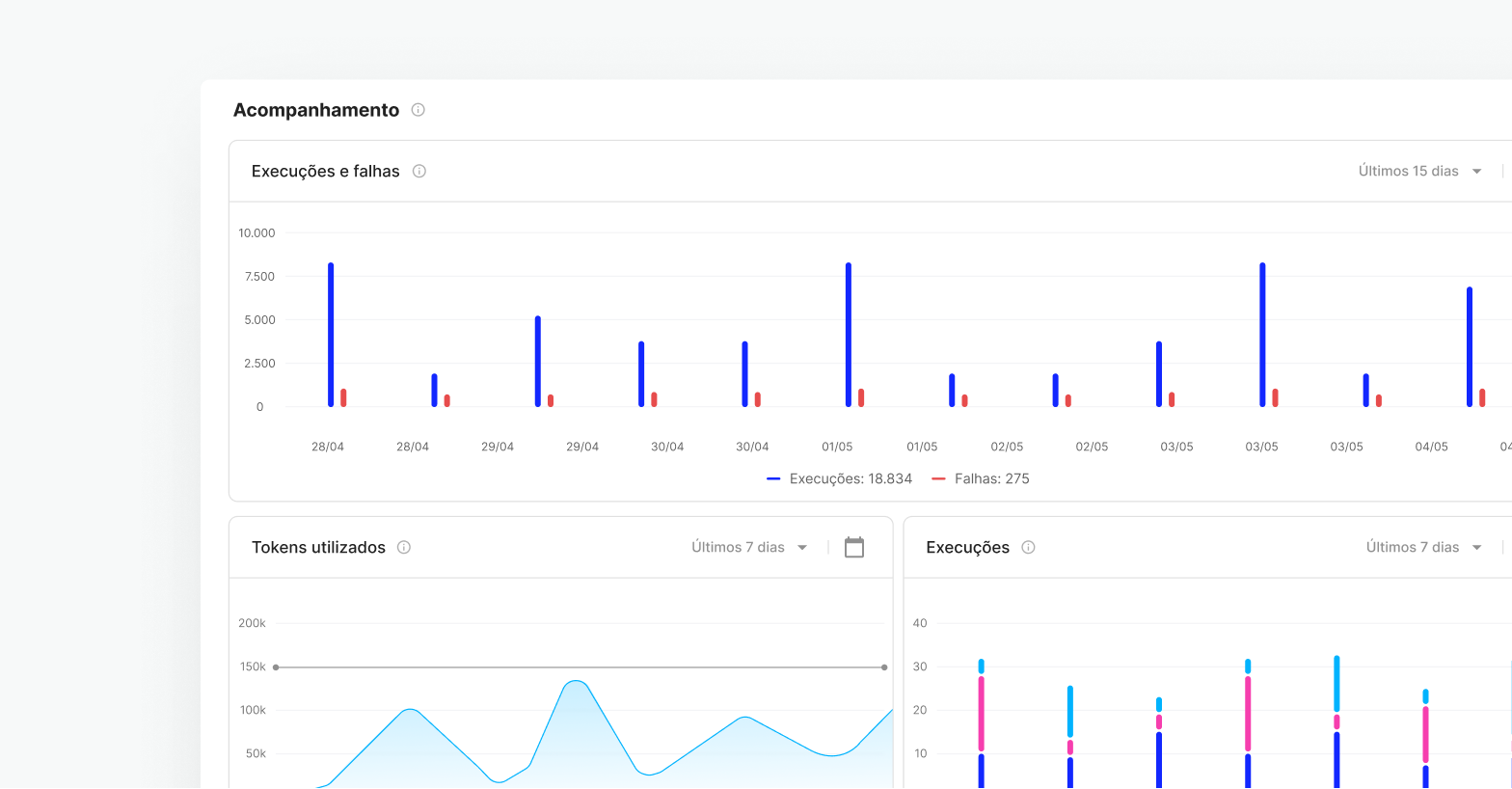
Gerenciamento centralizado
Configure e monitore o desempenho do seu servidor e o uso dos seus modelos em um único ambiente, o Skyone Studio, simplificando a gestão e o troubleshooting da sua operação de IA.
Veja as perguntas mais frequentes. Se precisar de mais informações, entre em contato conosco.